La diferencia entre estadística paramétrica y no paramétrica está basada en el conocimiento o desconocimiento de la distribución de probabilidad de la variable que se pretende estudiar.
En otras palabras la estadística paramétrica utiliza cálculos y procedimientos asumiendo que conoce como se distribuye una variable aleatoria \(X\) en particular para determinado análisis. Por el otro lado, la estadística no paramétrica utiliza métodos para conocer como se distribuye un fenómeno en particular para después utilizar metodologías de la estadística paramétrica.
Ambas son ramas de la estadística inferencial clásica.
Una muestra aleatoria simple (m.a.s) es un conjunto de variables aleatorias, independientes e idénticamente distribuidas, obtenidas a partir de la variable aleatoria \(X\) y que se distribuyen igual que la misma.
Definición 2.2Función de Distribución Empírica
Sea \(X_1,X_2,...,X_n \sim F\), una muestra aleatoria simple (m.a.s) con \(F\) función de distribución real. La Función de Distribución Empírica\(\hat F_n\) es la Función de distribución Acumulada (CDF) tal que pondera cada punto \(X_i\) con \(\frac{1}{n}\) (peso), es decir:
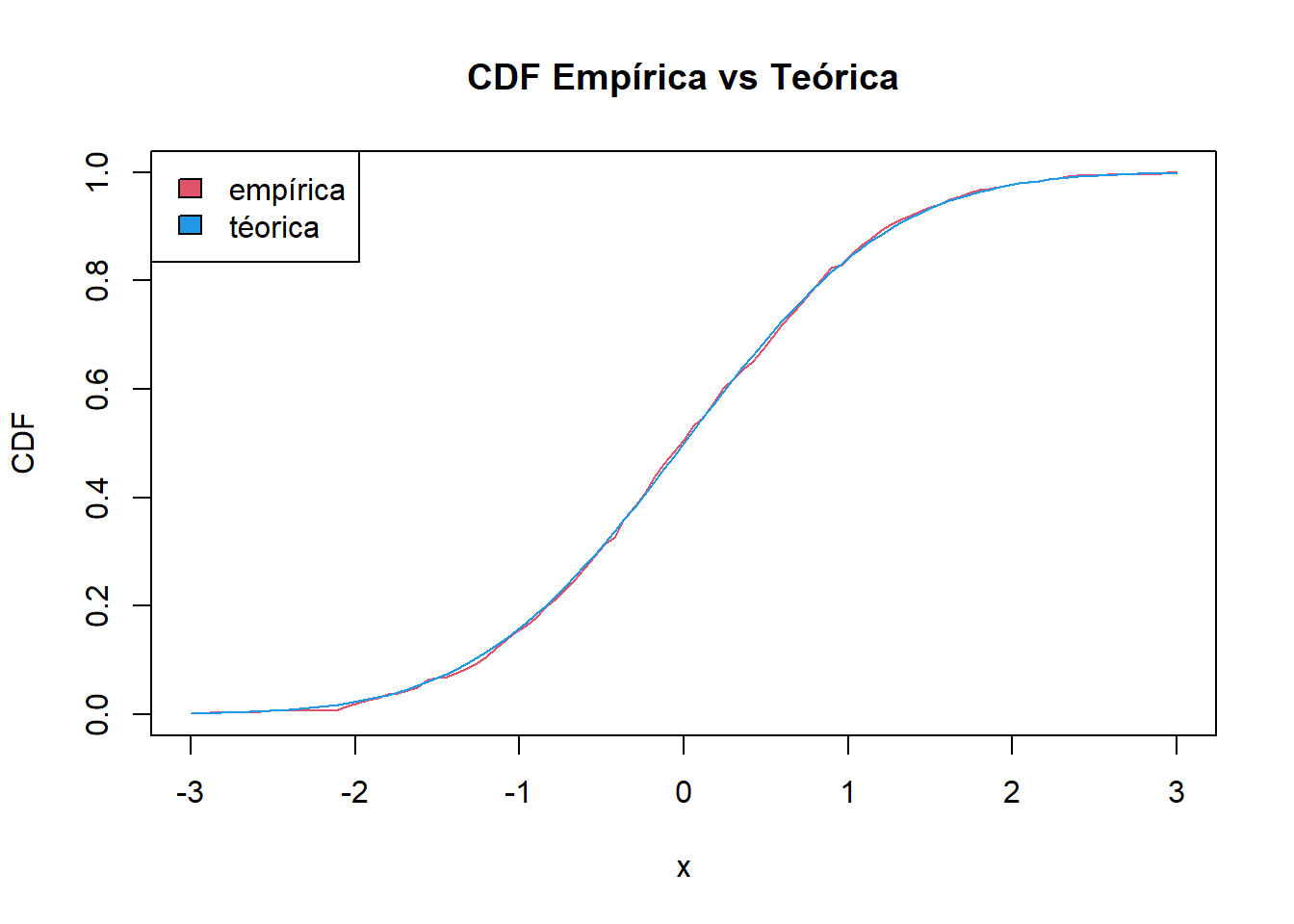
Para estimar \(P(-1 \leq X \leq 1) \approx \hat F_n(1)-\hat F_n(-1) \approx 0.692\)
(EmpiricalCDF(1,BD)-EmpiricalCDF(-1,BD))
[1] 0.692
Observe que la aproximación depende de la cantidad de los datos de la muestra para valores con pocas observaciones podría ocurrir que ciertos intervalos de probabilidad sean cero. Siguiendo el ejemplo:
Si estimamos la probabilidad que la variable aleatoria (v.a.) \(X\) esté entre 2.75 y 2.80, el resultado sería 0, según nuestra aproximación, pero el dato teórico sería de 0.0004246329.
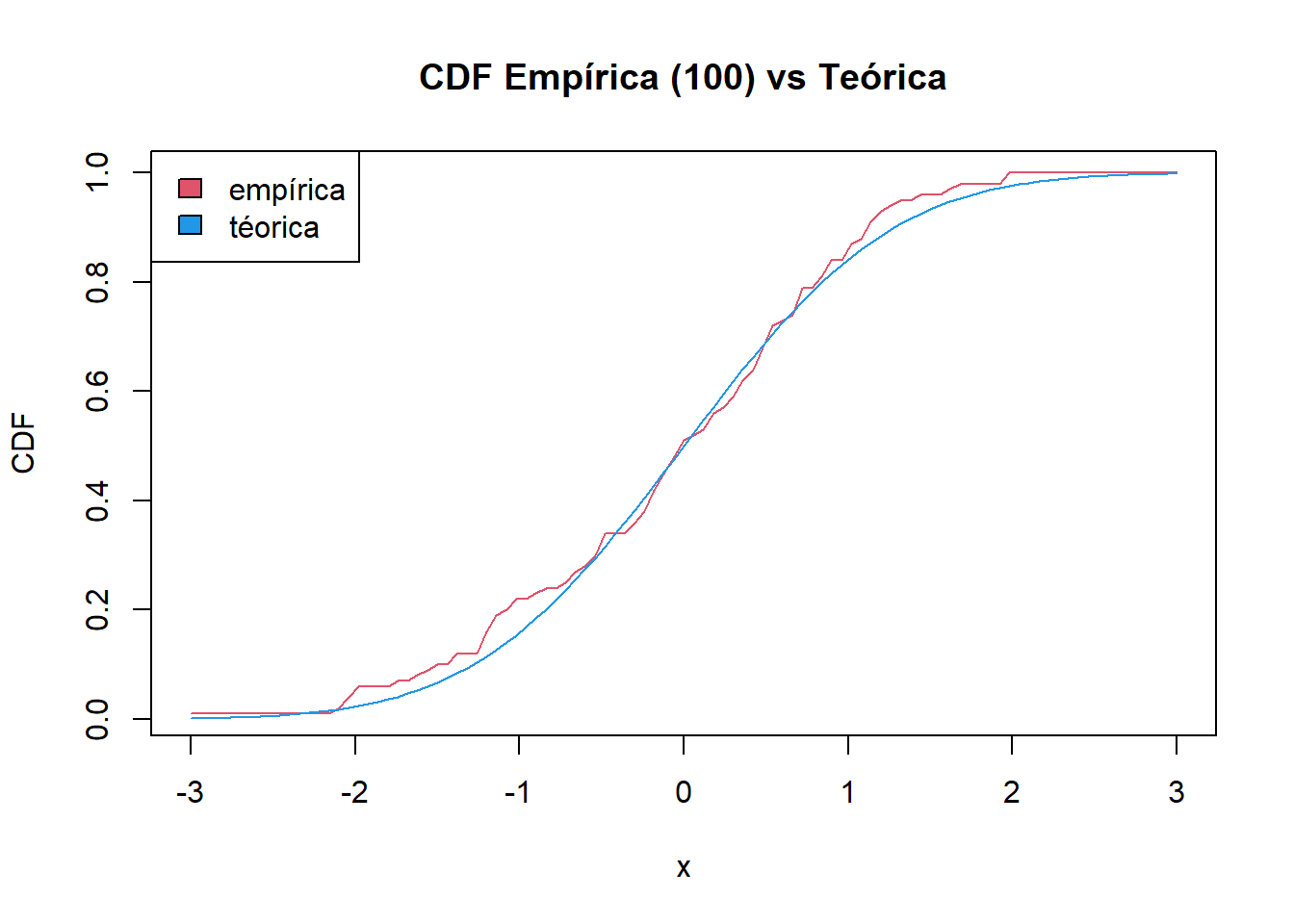
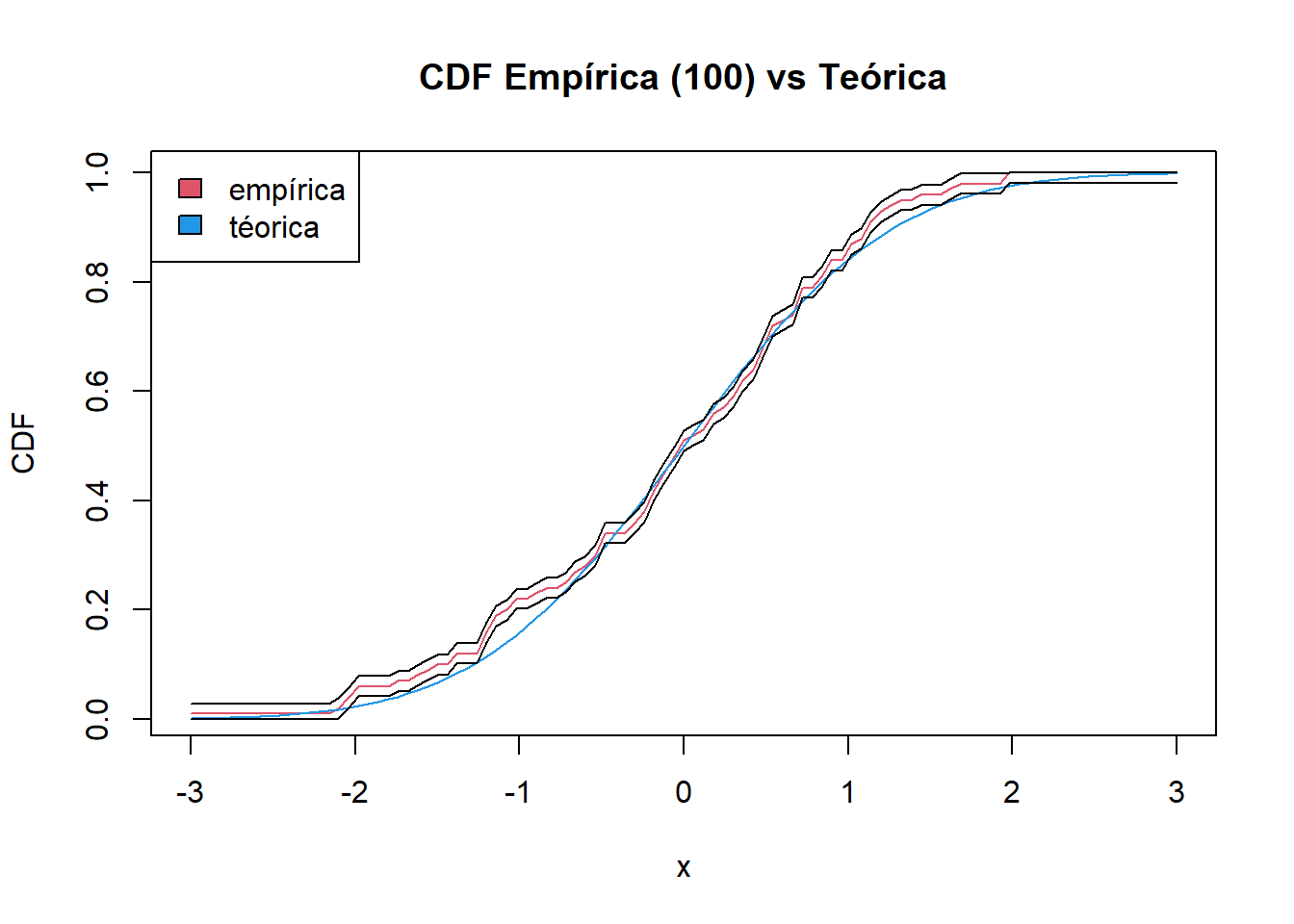
Otro caso extremo sería tener pocas observaciones, supongamos que nuestra muestra son solo 100 números, veamos como aumenta la diferencia entre la curva teórica y la curva empírica.
es decir \(\hat F_n(x)\) converge uniformemente a \(F(x)\).
Para Teorema 2.2 se puede usar la ley débil de los Grandes Números para demostrar la convergencia, pero también se puede usar la Ley Fuerte, en ese caso se puede probar que la convergencia es casi segura. Es decir que para cada \(x_i\) existe un conjunto de medida cero \(A_x\) tal que:
Continuando con el ejemplo desarrollado en el documento, para el caso de \(n=1000\), para determinar un intervalo de confianza del 95% (significancia = 5%), nuestro error \(\epsilon_n\) = \(\sqrt{\frac{1}{2(1000)}\ln(\frac{2}{0.05}))} = 0.0018\) y para el caso de \(n=100\) y el mismo nivel de significancia sería de \(0.0184\)
Un funcional estadístico\(T(F)\) es cualquier función de \(F\).
Ejemplo 2.3Ejemplos Funcionales Estadísticos
Sea una variable aleatoria \(X\) con cdf \(F\), algunos ejemplos de funcionales estadísticos son:
-La media: \(\mu=\int xdF(x)\).
-La varianza: \(\sigma^2=\int (x-\mu)^2dF(x)\)
-mediada: \(m=F^{-1}(1/2)\).
Definición 2.4Principio plug-in
La estimación plug-in de un parámetro \(\theta=T(F)\), donde \(T\) es un funcional estadístico de \(F\) se define como:
\[\hat \theta = T(\hat F_n)\] el estimador plug-in es un buen estimador cuando sólo conocemos una muestra \(X\), sin embargo este estimador no nos indica nada sobre al precisión de la estimación.
Definición 2.5Funcional lineal
Si \(T(F)=\int r(x)dF(x)\) para alguna función \(r(x)\) entonces \(T\) se le llama funcional lineal.
Esto dado que si F y G son funciones de distribución satisface:
\[T(aF+G)=aT(F)+T(G)\]
Dado que \(\hat F_n(x)\) es discreta, con un peso de \(1/n\) para cada \(X_i\) de la muestra, tenemos:
Si \(T(F)=\int r(x)dF(x)\) el estimador plug-in del funcional lineal es:
Para muchos cálculos requerimos encontrar un estimador para el error estándar ( desviación típica o desviación estándar) \(se\) del estimador plug-in \(T(\hat F_n(x))\), en algunos casos no es fácil de obtener esta medición, por lo que se requiere métodos como bootstrap que veremos más adelante para estimarlo, por el momento asumiremos que conocemos el estimador \(\hat{se}\).
Intervalo de Confianza con base Normal
Si \(T(\hat F_n(x)) \sim N(T(F),\hat{se}^2 )\), el intervalo de confianza con base normal con grado de significancia \(\alpha\) es el intervalo:
Si tomamos \(r(x)=x\) la función identidad obtenemos que \(T(F)=\int r(x)dF(x)=\int xdF(x)= \int xf(x)dx=\mu_x\) en caso continuo o \(\sum xp(X=x)=\mu_x\) en caso discreto. El estimador plug-in de \(\mu\) es
\[\hat\mu=\frac{1}{n}\sum_{i=1}^nr(X_i)=\frac{1}{n}\sum_{i=1}^n(X_i)=\bar X\] En caso que conozcamos la varianza \(\sigma^2\) sabemos que \(se=\sigma/\sqrt{n}\), si no lo conocemos podríamos estimar \(\sigma\) por medio de \(\hat \sigma\), entonces \(\hat{se}=\hat \sigma/\sqrt{n}\).
La estimación de las curvas de densidad no paramétricas, utiliza técnicas similares para problemas de regresión no paramétricas que se conocen como curvas de estimación o suavizado de curvas (smoothing). Esta parte es tomada del Wasserman (2006), Aguilar (s.f.) y Ojeda (2014)
Sea \(g\) una función de densidad desconocida y \(\hat g_n\) un estimador de \(g\). Observe que \(\hat g_n(x)\) varía según los datos de la muestra.
Una función de pérdida de información es el error cuadrático integrado (ISE) y se define como:
\[L(g,\hat g_n)=\int(g(u)-\hat g_n(u))^2du\]
Definición Error Cuadrático Medio integrado (MISE)
Se define como una medida de riesgo al error cuadrático medio integrado (MISE) como:
\[R(g,\hat g_n)=E[L(g,\hat g_n)]\]
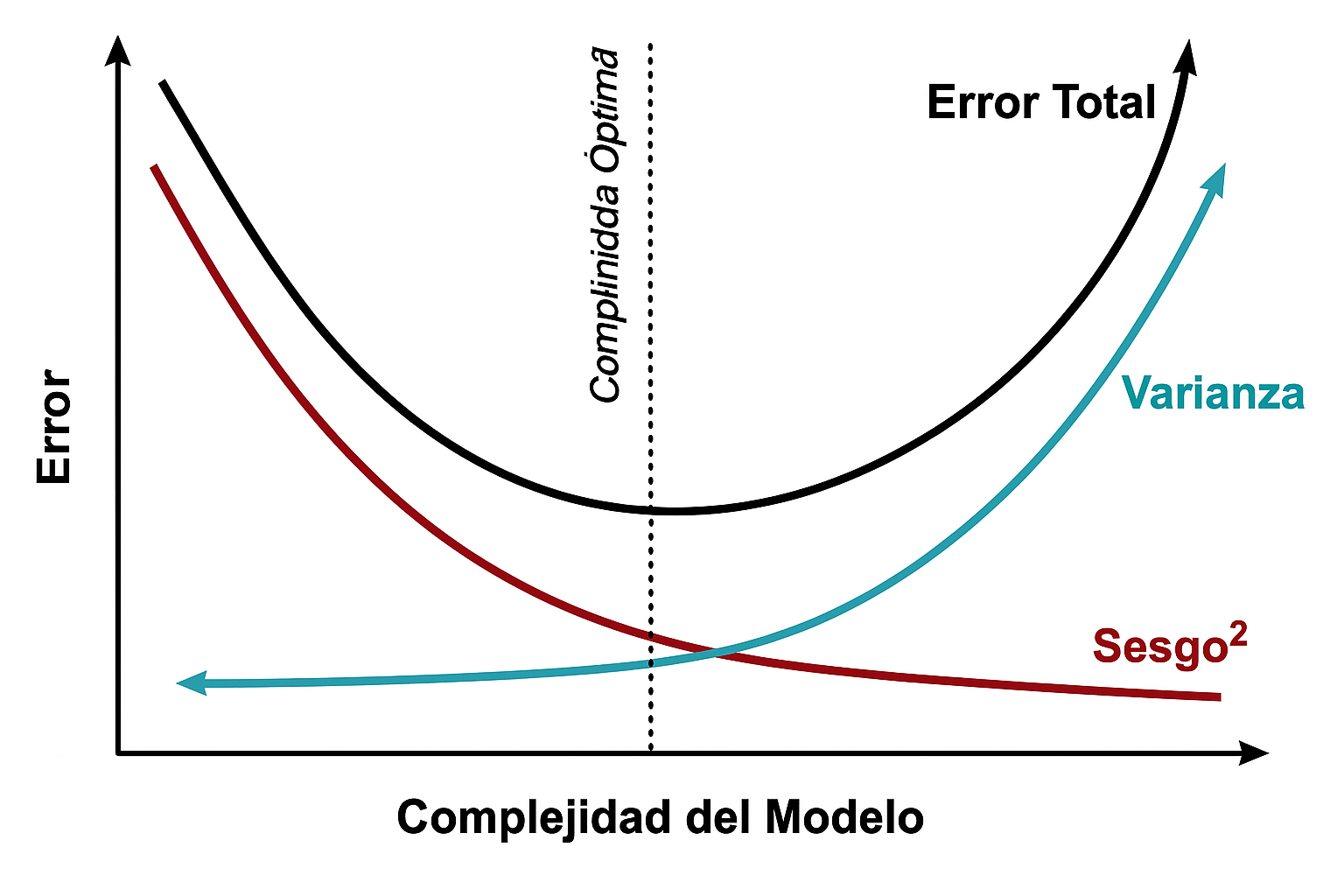
Lema 2.1Riesgo Total Sea \(b(x)\) el sesgo y \(v(x)\) la varianza de \(\hat g_n(x)\) respectivamente para un \(x\) fijo. Entonces:
\[R(g,\hat g_n)=\int b^2(x)dx+\int v(x)dx\]
el Lema 2.1 nos indica que existe una relación entre el sesgo de nuestro estimador y su varianza, situación similar con el Error cuadrático Medio, que se conoce como compensación sesgo-varianza o bais-variance tradeoff. Que el Riesgo o Error Total lo podemos separar como la suma de dos errores el del sesgo y el de la varianza.
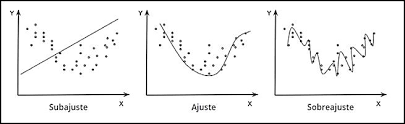
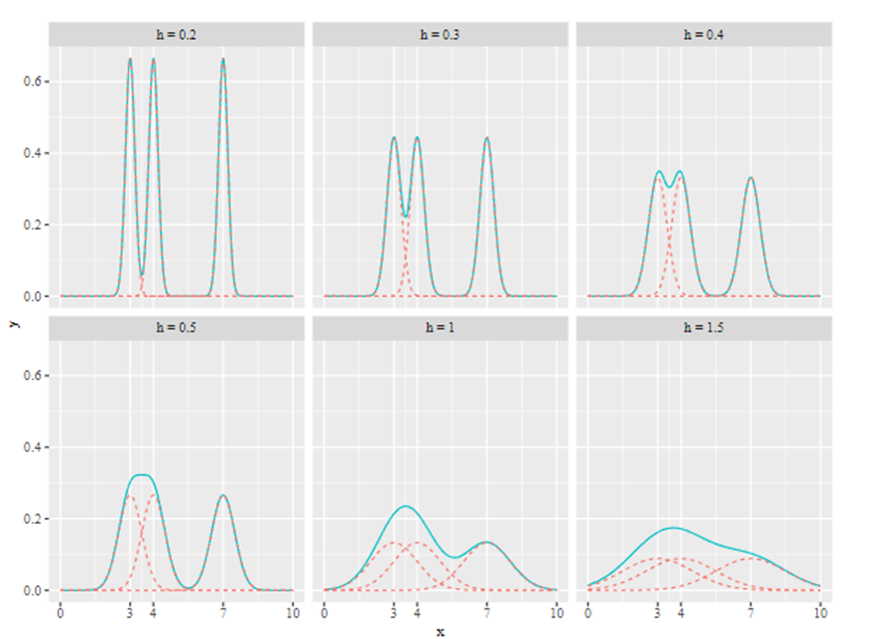
Si buscamos una \(\hat g_n(x)\) con poca variabilidad, el cuadrado del sesgo aumenta, esta condición se conoce como subajuste (underfitting), esto ocurre cuando un modelo es muy sencillo y no captura toda la información de la muestra, la curva tiende a ser muy suavizada
Si buscamos una \(\hat g_n(x)\) con un sesgo mínimo, la varianza tiene a aumentar, esta condición se conoce como sobreajuste (overfitting), esto ocurre cuando un modelo captura toda la información de la muestra, donde prácticamente la curva \(\hat g_n(x)\) coincide prácticamente con todos los todos los puntos de la muestra, la curva no es suave.
Un ajuste balanceado o equilibrado, es cuando el Riesgo se minimiza.
Ejemplo sobreajuste, ajuste y subajuste
A nivel del Riesgo o Error total, se puede graficar el tradeoff de un modelo como el siguiente:
tradeoff bais-variance
2.3.2 Histograma
Problema
Dada una m.a.s. de \(N\) observaciones \(X=x_1,x_2,...,x_N\), se quiere estimar una función de densidad \(g\) desconocida.
Una primera aproximación para estimar la función \(g\) es utilizando un histograma.
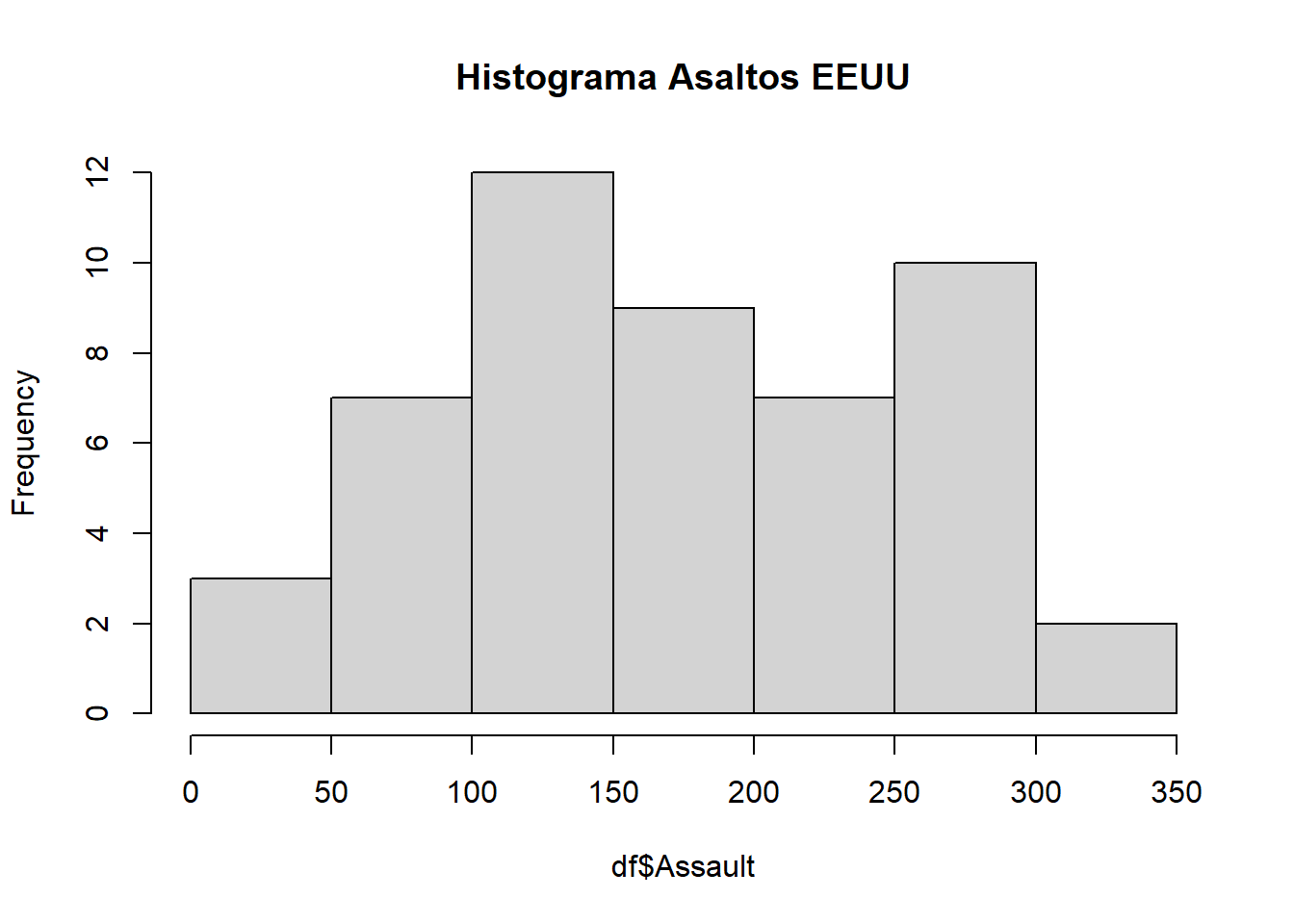
Realizaremos un ejemplo con los datos de una distribución de asaltos en Estados Unidos, como primer acercamiento realizaremos un histograma.
df<-USArrestssummary(df)
Murder Assault UrbanPop Rape
Min. : 0.800 Min. : 45.0 Min. :32.00 Min. : 7.30
1st Qu.: 4.075 1st Qu.:109.0 1st Qu.:54.50 1st Qu.:15.07
Median : 7.250 Median :159.0 Median :66.00 Median :20.10
Mean : 7.788 Mean :170.8 Mean :65.54 Mean :21.23
3rd Qu.:11.250 3rd Qu.:249.0 3rd Qu.:77.75 3rd Qu.:26.18
Max. :17.400 Max. :337.0 Max. :91.00 Max. :46.00
cat("histograma \n")
histograma
hist(df$Assault, main="Histograma Asaltos EEUU")
En general para la muestra \(X=x_1,x_2,...,x_N\) del problema, se debe hallar un intervalo de soporte \(S=[a,b]\), tal que, \(a \leq x_i \leq b \; \forall x_i \in X\).
El intervalo \(S\) se divide en \(K\) partes iguales (particiones o bins) de longitud \(\frac{b-a}{K}\) tal que:
Sea \(N_k\) el número de observaciones de la muestra \(X\) en el intervalo \(I_k\), es decir:
\[ N_k=\sum_{i=1}^N I_{\left( a+(k-1)\left( \frac{b-a}{K}\right), a+k\left( \frac{b-a}{K}\right) \right)} \; k=1,...,K\] Si tomamos la proporción de \(N_k\) con respecto al total de observaciones \(N\) esta es un estimador de que \(x_i\) pertenezca a \(I_k\), es decir:
\[E\left[\frac{N_k}{N}\right]=P\left( a+(k-1)\left( \frac{b-a}{K}\right)\leq x_i \leq a+k\left( \frac{b-a}{K}\right) \right)\] Como estamos con el caso de los histogramas, para cada \(I_k\), todos los puntos son iguales, un estimador para la densidad \(g(x)\) sería.
Por el teorema de valor medio de integrales, existe un \(\tilde a\) tal que:
\[g(\tilde a)=\frac{1}{(b-a)/K}\int_{a+(k-1)\left( \frac{b-a}{K}\right)}^{a+k\left( \frac{b-a}{K}\right)}g(x)dx\] Por lo que para un determinado valor c, su sesgo \(b(c)\) sería \(g(c)-g(\tilde a)\).
Observe que cuando \(K\) aumenta disminuye la longitud del intervalo y esto reduce el sesgo \(b(c)\), es decir:
\[\lim_{K\to\infty}g(\tilde a)=g(c).\]
Se podría pensar que entre más grande sea \(K\), es decir que sea más pequeño \(h=\frac{b-a}{K}\) es mejor, sin embargo, esta situación produce un sobreajuste al modelo aumentado la variabilidad del modelo.
2.3.4 Variabilidad del estimador
La probabilidad que \(X_i\) pertenezca a \(I_k\) esta dada por \(\hat p=g(\tilde a)\frac{b-a}{K}\), en otras palabras, la probabilidad sigue una distribución binomial con parámetro \(\hat p\), por lo que:
\[var[\hat p]=\hat p (1-\hat p)\frac{1}{N}=g(\tilde a)\frac{b-a}{K} \left( 1-g(\tilde a)\frac{b-a}{K}\right)\frac{1}{N}\]
Observe que si \(K\) aumenta, la \(var[g(\tilde a)]\) aumenta, y si \(N\) aumenta la varianza disminuye.
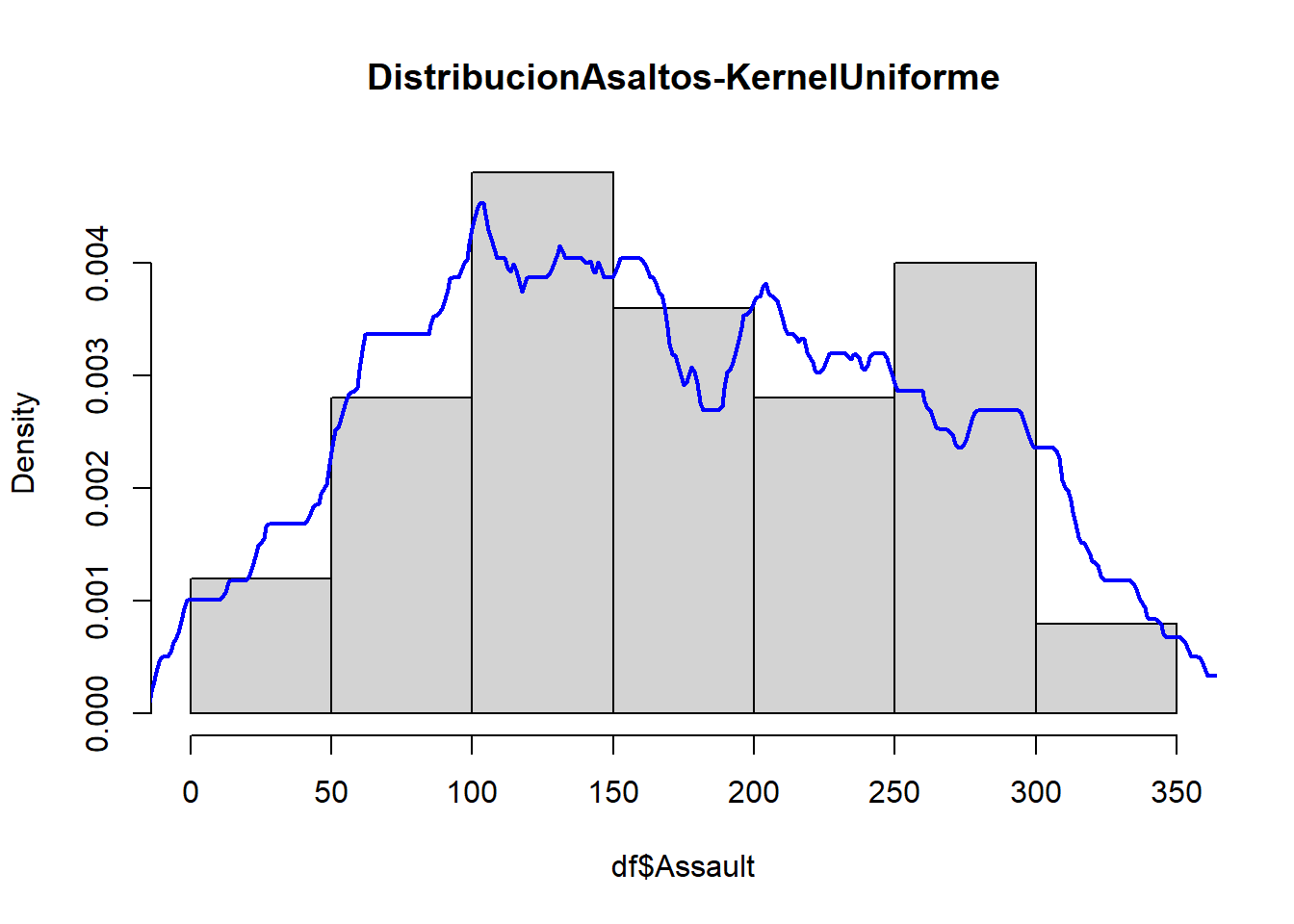
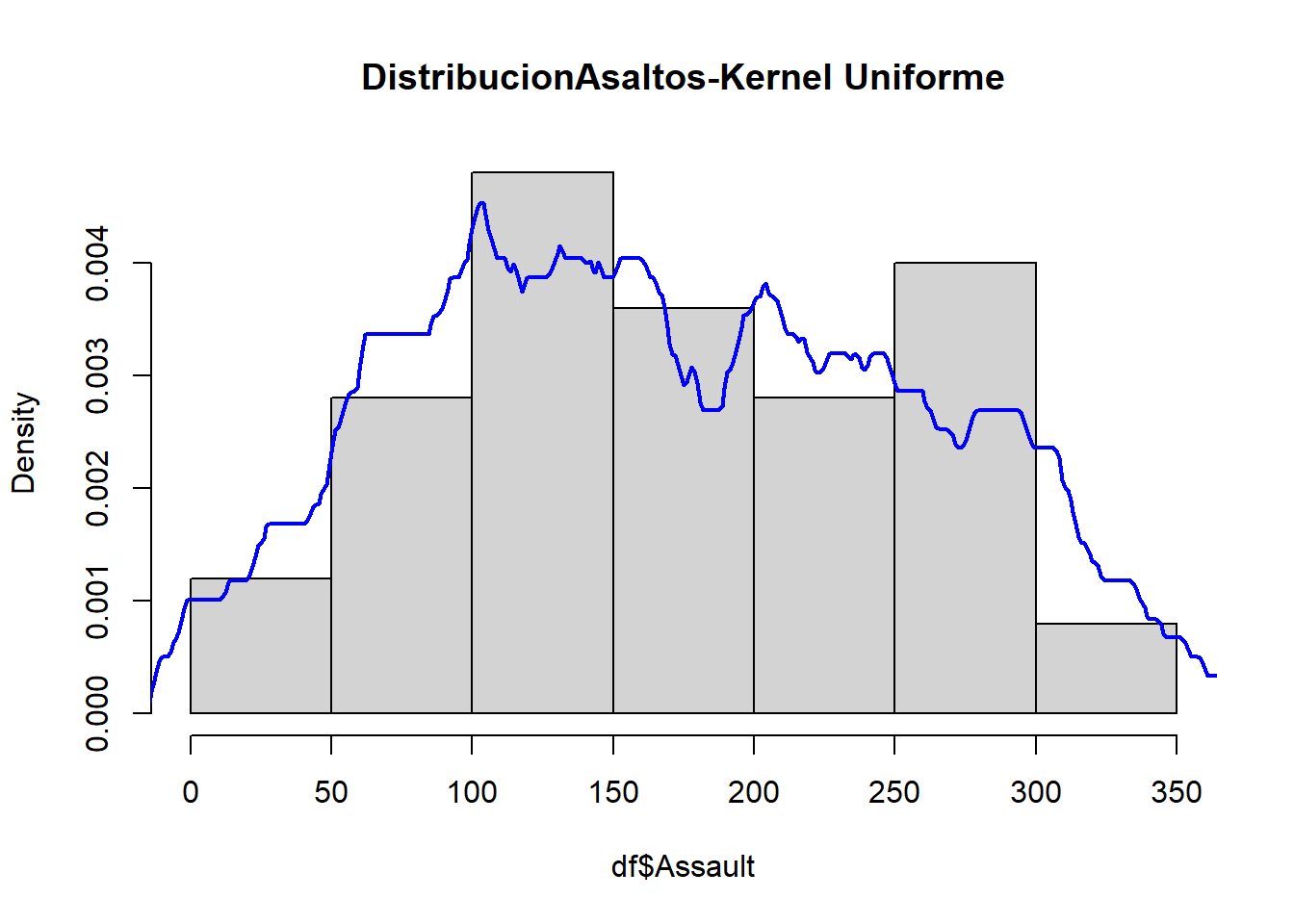
2.3.5 Densidad por Kernel Uniforme
Un problema con el histograma para estimar la densidad de una variable es que los puntos adyacentes puede ser muy distintos si están de un lado u otro de la frontera de un intervalo. En otras palabras, hay cambios discontinuos en el estimador de la densidad justo en la frontera de cada bin (partición). Esto genera mayor sesgo cerca de la frontera del intervalo que en el centro.
Si asumimos para un punto \(c\) que es el centro del intervalo \(I_k\) de longitud \(h\) como referencia obtendríamos como función de estimación para \(g(x)\) a:
\[\hat g (c) = \sum_{i=1}^N I_{\left( c-h \leq x_i \leq c+h \right)}\frac{1}{2hN}\] Esta metodología se conoce como estimador de densidad por kernel uniforme.
2.3.6 Estimador del vecino más cercano (nearest neighbor).
Este estimador de una densidad, es usual para problemas de 2 o más dimensiones, en esta metodología para el valor \(c\), se toma la observación más cercana dada una distancia específica \(d\) y posteriormente se escogen los \(K\) vecinos más cercanos según la distancia.
Sea \(d_K(x)=\underset{t}{\mathrm{argmin}} I_{(d(x_i,x)\leq t)}\geq K\) dado un t. y
\[\hat g (c)=\frac{K-1}{2d_K(x)N}\]
donde las distancias más usuales en esta metodología es la euclidiana y la de manhattan ( distancia \(L_1\)).
Leer: Zhao Puning Lai Lifeng “Analysis of KNN Density Estimation” ( Zhao & Lai (2020) ).
2.4 Estimadores no paramétricos de funciones de Densidad.
Rosenblatt en 1956 en su publicación “Remarks on some nonparametric estimatees of a density function” ( Rosenblatt (1956) ) propone una metodología para aproximar la densidad de una muestra más suave y con convergencia más rápida que la de los histogramas.
2.4.1 Kernels
Una función kernel (\(K(x)\)) cumple con la siguientes características:
Continua
Simétrica respecto a eje \(y\)
No negativa
Una constante \(C \in \mathbb R^{+}\) por un kernel es un kernel.
Sumas de kernels es un kernel.
Además de estas características vamos a solicitar que \(K(x)\) sea una función de densidad, y que cumpla que:
\(\int K(x)dx=1\)
\(E_k[x]=\int xK(x)dx=0\)
\(var_k[x]=\int x^2K(x)dx < \infty\)
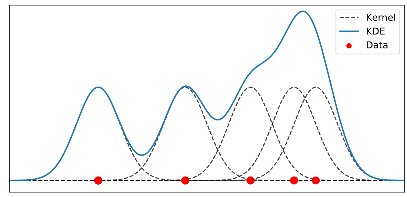
Ejemplo Estimación de densidad por kernel
2.4.2 Parametrización de Kernels
Sea \(K(x)\) una función kernel, definida de la siguiente manera:
\[K(x)= \begin{cases}
f(x) & x \in [-a,a] \\
0 & \text{en otro caso}
\end{cases}\]
Sea \(h \in \mathbb R^{+}\), un kernel parametrizado en \(h\) es:
\[K_h(x)=\begin{cases}
\frac{1}{h}K\left( \frac{x}{h} \right) & x \in [-ah,ah] \\
0 & \text{en otro caso}
\end{cases}\]
Es claro que \(K_h(x)\) sigue cumpliendo las propiedades de un Kernel, es decir que \(K_h(x)\) es:
Continua
Simétrica respecto a eje \(y\)
No negativa
Una constante \(C \in \mathbb R^{+}\) por un kernel es un kernel.
Sumas de kernels es un kernel.
Para determinar que si es una función que se puede utilizar para la metodología de estimación de densidades por kernel, basta con determinar si:
\(\int K_h(x)dx=1\)
\(E_{kh}[x]=\int xK_h(x)dx=0\)
\(var_{kh}[x]=\int x^2K_h(x)dx < \infty\)
Prueba
\[\int K_h(x)dx=\int_{-ah}^{ah} \frac{1}{h}K\left( \frac{x}{h} \right)dx\] tome \(u=x/h \Rightarrow du = \frac{1}{h}dx\)
\[\int K_h(x)dx=\int_{-a}^{a} K\left( u \right)du=1\]
\[E_{kh}[x]=\int xK_h(x)dx=\int_{-ah}^{ah} \frac{x}{h}K\left( \frac{x}{h} \right)dx=h\int_{-a}^{a} uK\left( u \right)du=0\]
\[var_{kh}[x]=\int x^2K_h(x)dx=\int_{-ah}^{ah} \frac{x^2}{h}K\left( \frac{x}{h} \right)dx=h^2\int_{-a}^{a} u^2K\left( u \right)du < \infty\]
La parametrización de un kernel como el indicado, sigue siendo un kernel. El paramétro \(h\) posee un rol importante para la estimación de densidades:
Si \(h>1\), la amplitud de función \(K\) se aumenta, pero el factor \(1/h\) reduce la amplitud de \(K\) para mantener el área igual a 1.
Si \(h<1\), se reduce la amplitud de \(K\), pero el factor \(1/h\) amplía el rango para que se mantenga el área igual a 1.
2.4.3 Traslación de Kernels
Podemos generalizar el concepto de kernels, cambiando la propiedad de simetría respecto a eje \(y\), a un ser simétrica con respecto a la recta \(y=x_i\) con \(x_i \in mathbb R\). El kernel parametrizado en \(h\) y centrado en \(x_i\) es
\[K_h(x)=\begin{cases}
\frac{1}{h}K\left( \frac{x-x_i}{h} \right) & x \in [x_i-ah,x_i+ah] \\
0 & \text{en otro caso}
\end{cases}\]
Se puede verificar que esta traslación cumple con:
\(\int K_h(x)dx=1\)
\(E_{kh}[x]=\int xK_h(x)dx=c\)
\(var_{kh}[x]=\int x^2K_h(x)dx < \infty\)
Ejercicio para el lector.
2.5 Estimación de Densidad por Kernel
Para la muestra \(X=x_1,x_2,...,x_N\), se debe hallar un intervalo de soporte \(S=[a,b]\), tal que, \(a \leq x_i \leq b \quad \forall x_i \in X\).
Si utilizamos una función kernel \((k(x))\), de peso para cada punto de observación, con una longitud \(h\) podemos estimar una función de densidad \(f(x)\) en el punto \(c\) como:
\[E[\hat f(c)]=E\left[\frac{1}{hN}\sum_{i=1}^NK\left(\frac{x_i-c}{h} \right)\right]=\frac{1}{h}E\left[K\left(\frac{x_i-c}{h} \right)\right]=\frac{1}{h}\int K\left(\frac{x-c}{h} \right)f(x)dx\] si tomamos \(y=\frac{x-c}{h}\), entonces:
\[E[\hat f(c)]=\int K(y)f(c+hy)dy\]
si \(h \to 0 \Rightarrow E[\hat f(c)]=f(c)\).
Dado que \(h\) es pequeño, es lo que buscamos, podemos realizar un desarrollo de Taylor alrededor de punto \(c\) ( asumiendo que \(f''(x)<\infty\)), es decir:
El término \(\frac{1}{4}(f''(c)var_k[y])^2+\frac{1}{hN}f(c)\sigma_k\) se le llama error cuadrático medio asintótico (AMSE)
2.5.3 Selección del Bandwidth (\(h\))
El término \(h\) se conoce como ventana o ancho de banda o Bandwidth y como vimos anteriormente con el caso del Histograma, la selección de esta variable es importante para no caer en un sobreajuste o en un subajuste que suavice adecuadamente las curvas de densidad.
Si minimizamos el \(h\) del AMSE de \(\hat f(c)\) obtenemos:
\[h_{opt}=\left( \frac{4f(c)\sigma_k}{N(f''(c)var_k[y])^2}\right)^{1/5}=C*N^{-1/5}\] Es decir el \(MSE_{opt}= O(N^{-1/5})\).
En otras palabras, el error cuadrático medio disminuye cuando N aumenta pero a una velocidad muy despacio a un factor de 1/5.
También se puede optimizar el bandwidth, usando el MISE.
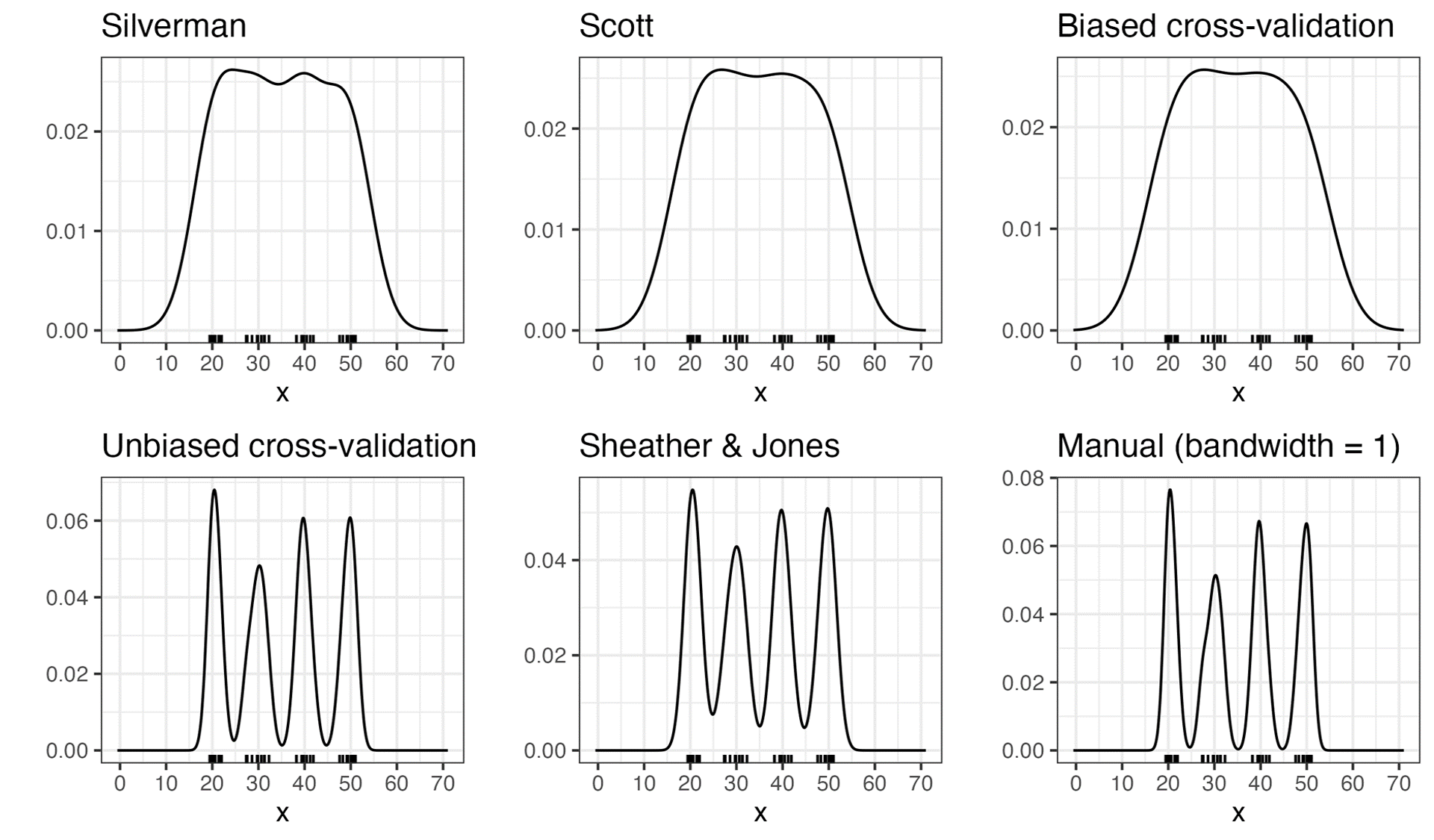
diferentes ejemplos de Bandwidth
Los principales métodos empíricos para obtener el \(h\) optimo son:
Scott’s rule \(h \approx 1.06 \hat S N^{(-1/5)}\) donde \(\hat S\) es la cuasidesviación estandar.
Silverman’s rule \(h \approx 0.9 min( \hat S, \frac{IQR}{1.35}) N^{(-1/5)}\) donde \(IQR\) es el rango intercuartil ( diferencia entre el tercer y primer cuartil)
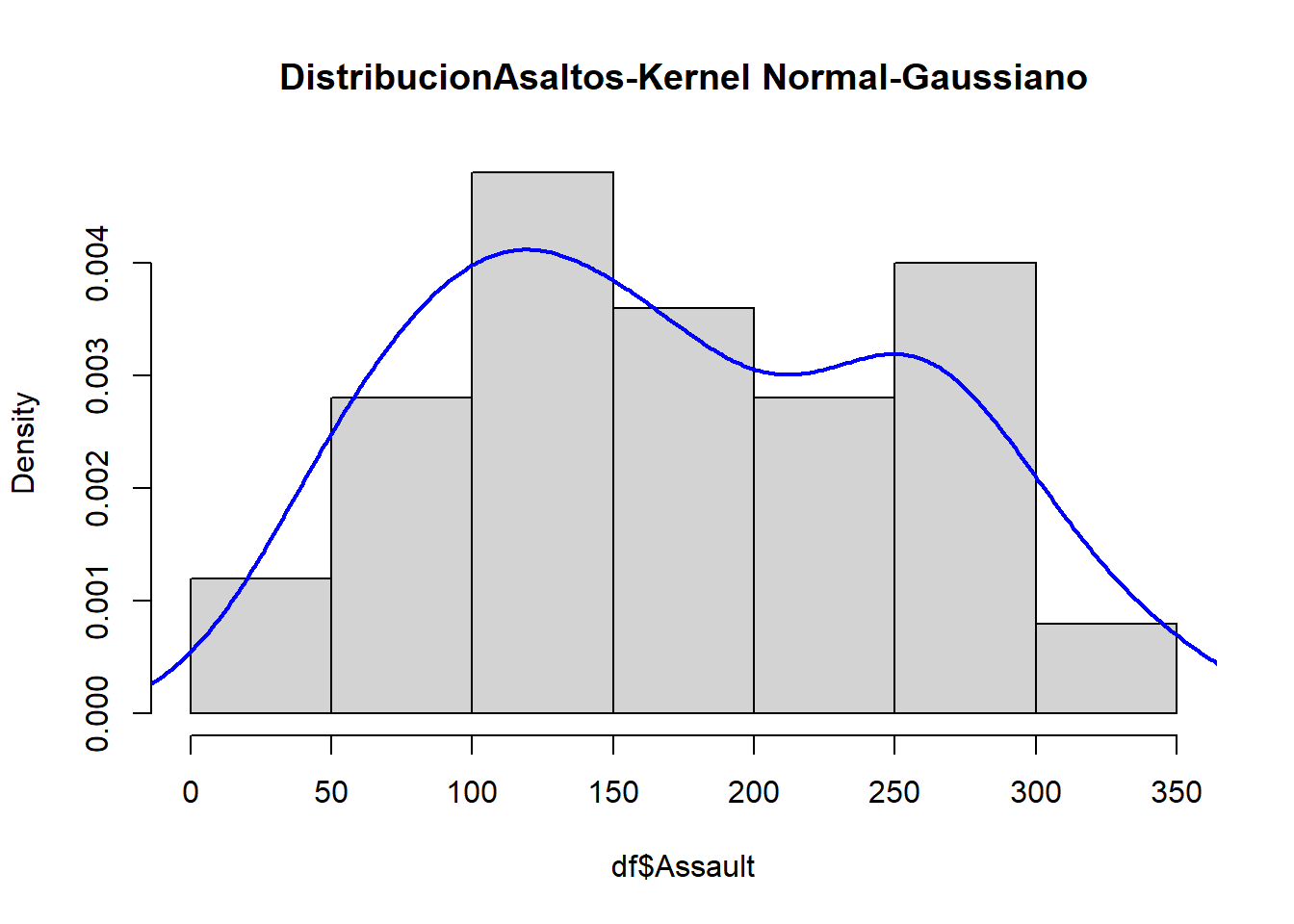
Para el caso de Silverman’s rule se asume que el núcleo (kernel) es gaussiano.
Se puede realizar metodología de validación cruzada (cross-validation) para obtener el optimo, estas metodología puede ser sesgada o insesgadas.
Improved Sheather & Jones: Es un algoritmo recursivo que minimiza el ASIME ( error cuadrático medio asintótico integrado) que depende del cuadrado de \(f''(x)\), es recomendado para datos no normales o multimodales.
ejemplos de metodologías para Bandwidth
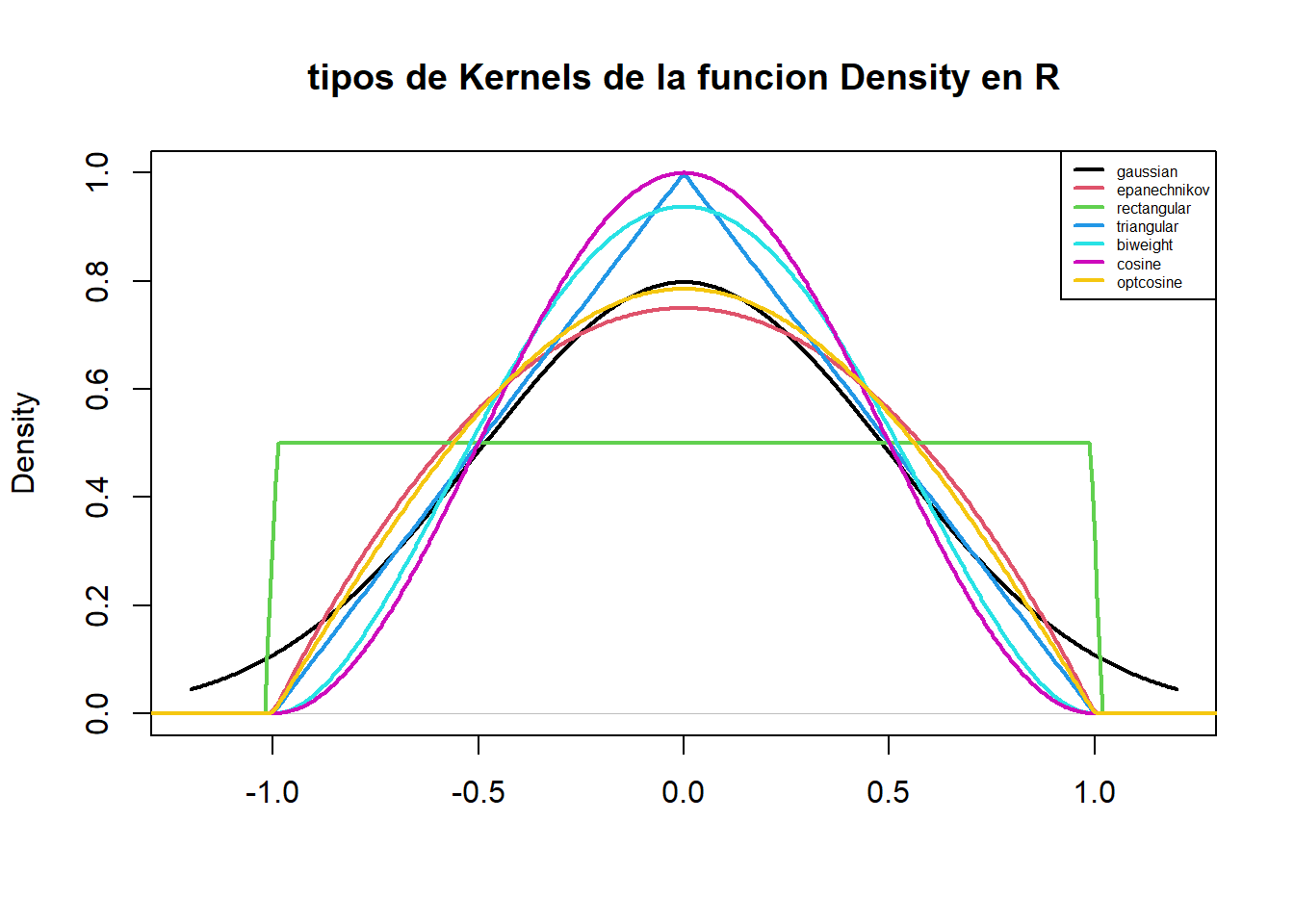
2.5.4 Modelos de Kernels
Existen varios modelos de kernels utilizados para estimar la densidad de ciertos datos. En el siguiente gráfico se muestra un ejemplo de varios tipos de kernels
plot(density(0, from =-1.2, to =1.2, width =2, kernel ="gaussian"),type ="l", ylim =c(0,1), xlab ="",main ="tipos de Kernels de la funcion Density en R", lwd=2)for(i in2:length(kernels))lines(density(0, width =2, kernel = kernels[i]), col = i, lwd=2)legend("topright", legend = kernels, col =seq(kernels), lty =1,lwd =2,cex =0.5)
Kernel Rectagular o Uniforme
Es un rectángulo que centrado sobre cada punto. Al interactuar con los kernels de los otros puntos, el efecto de la suma es un cambio abrupto.
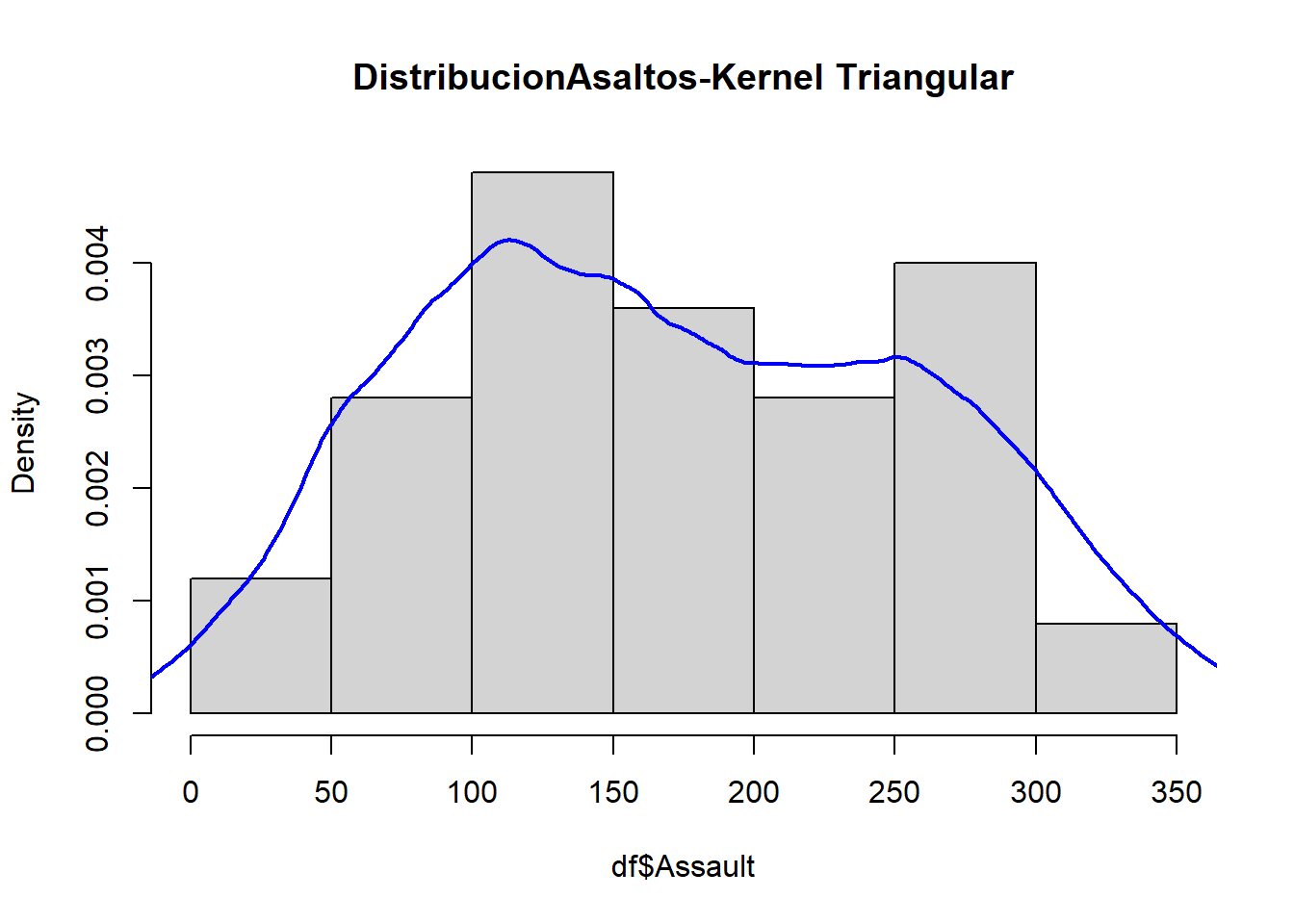
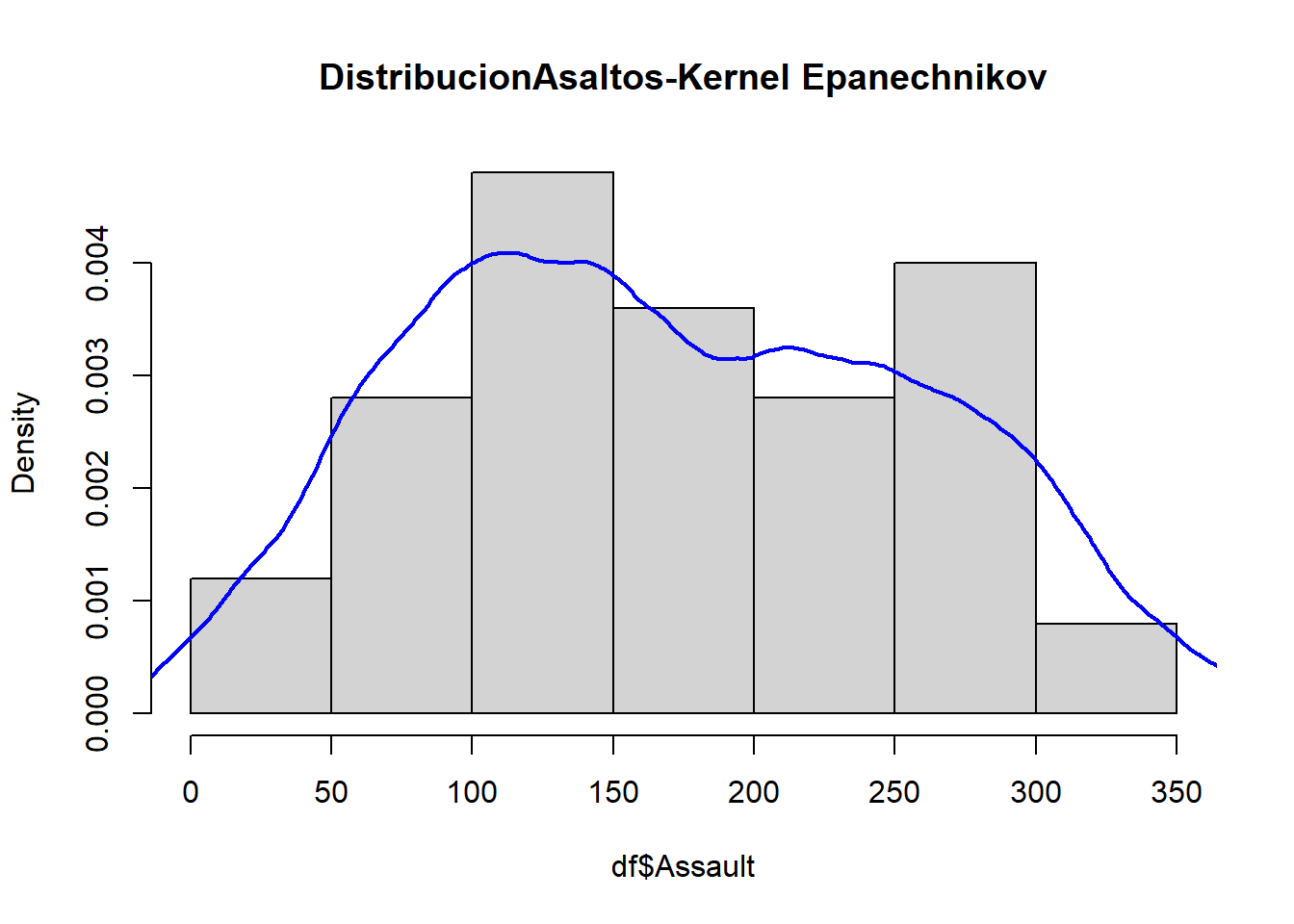
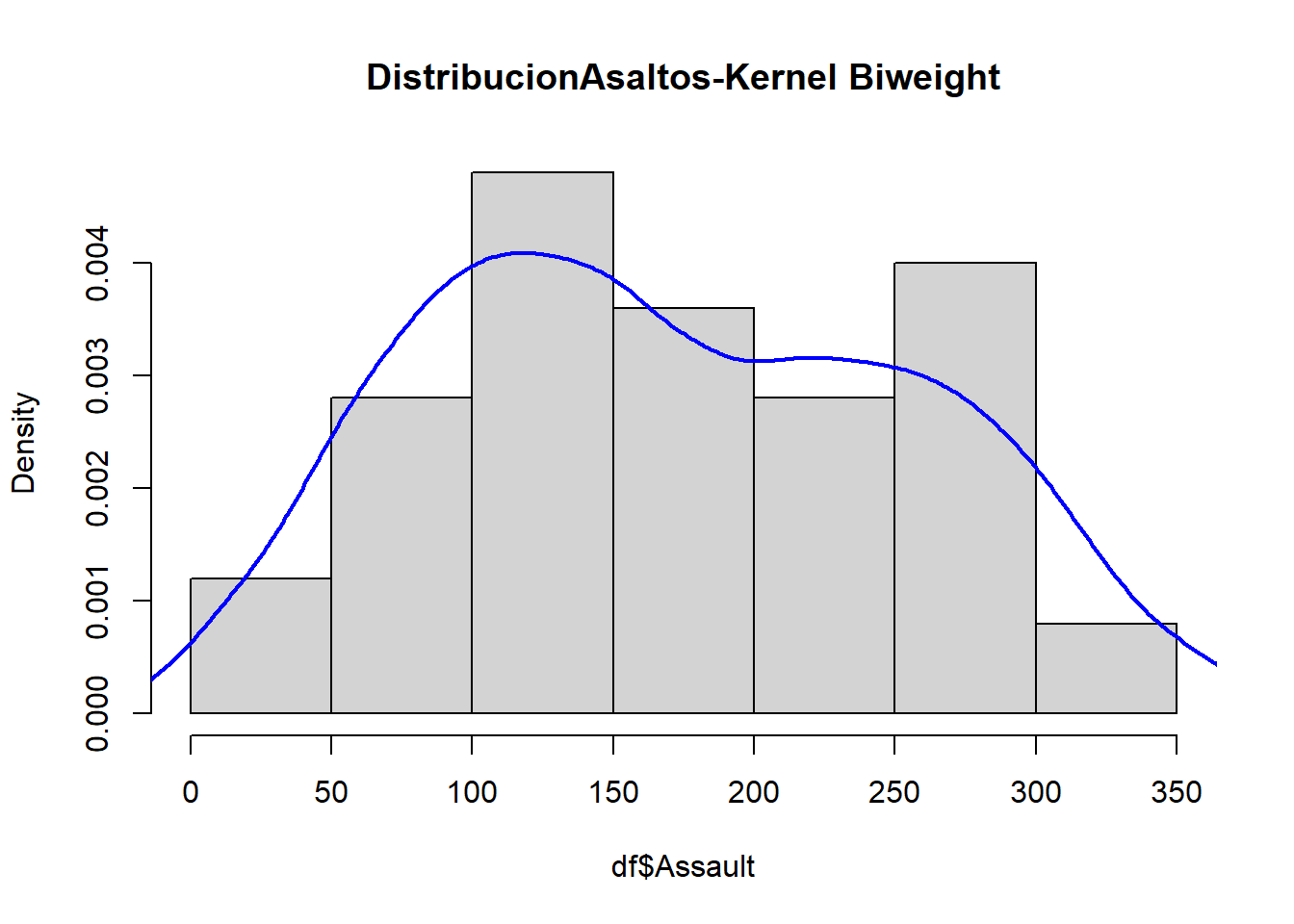
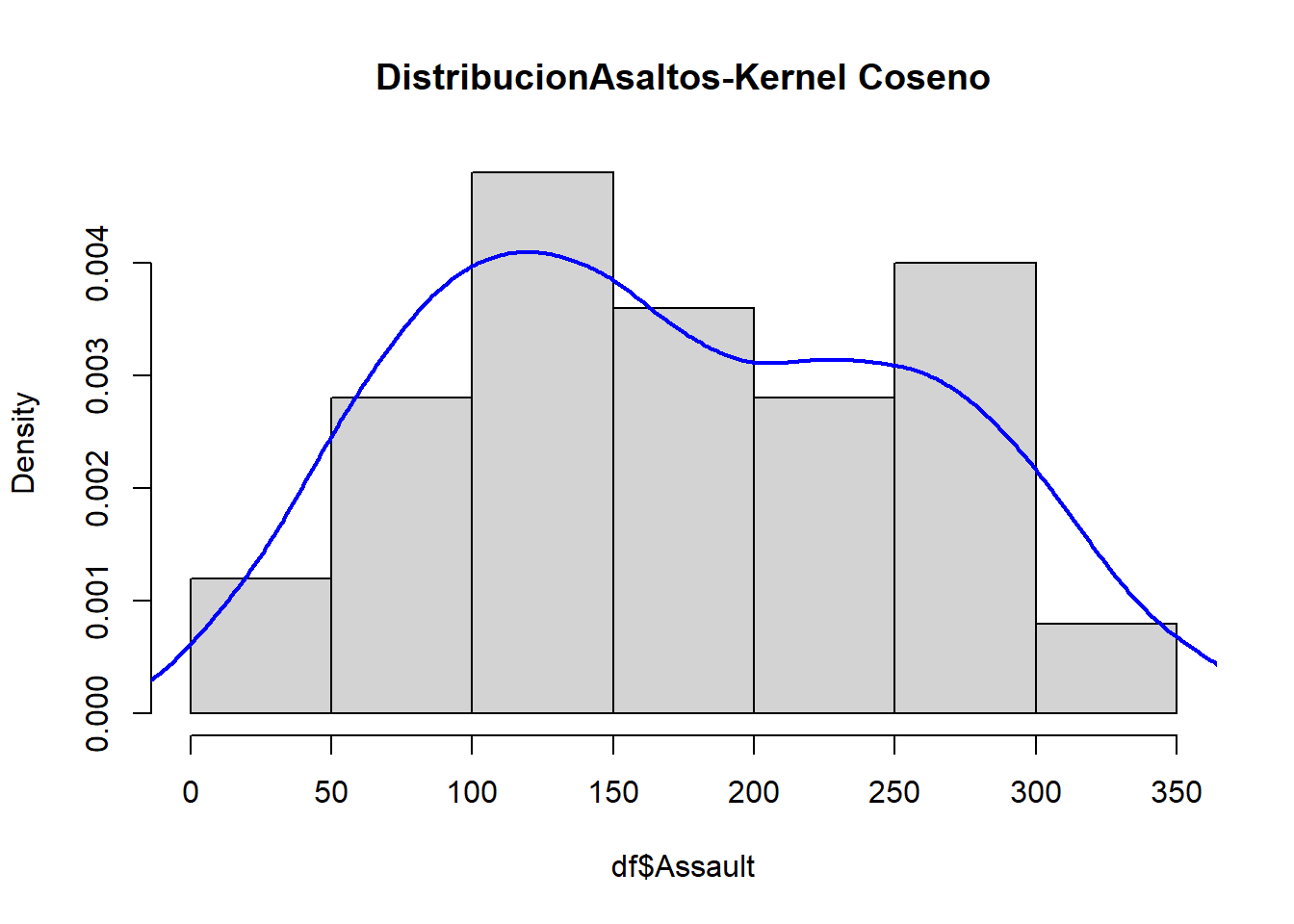
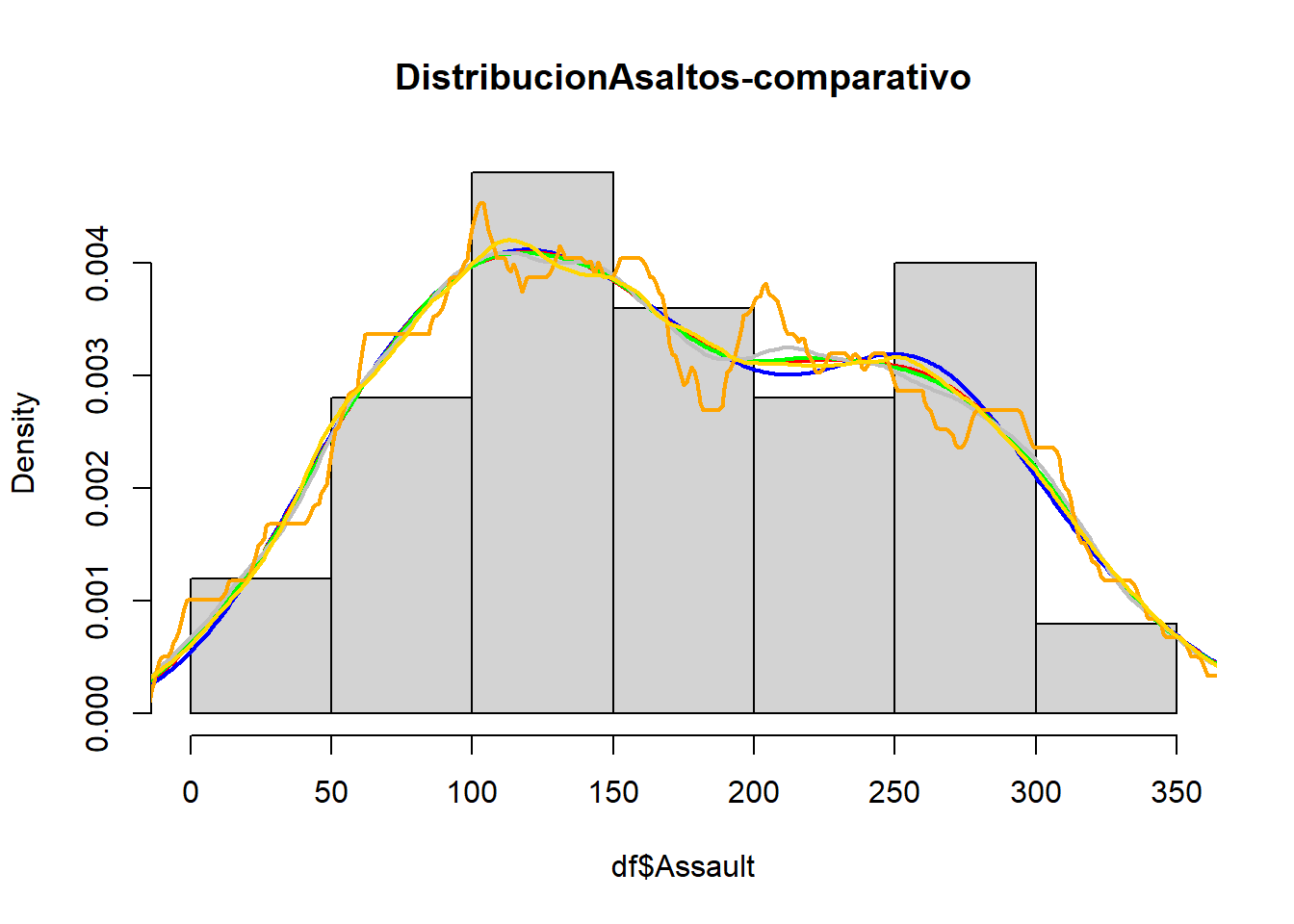
En el siguiente gráfico se puede comparar cada uno de los estimadores de la densidad de los asaltos en Estado Unidos.
D1=density(df$Assault,kernel="gaussian") #esta es por defectoD2=density(df$Assault,kernel="cosine")D3=density(df$Assault,kernel="biweight")D4=density(df$Assault,kernel="epanechnikov")D5=density(df$Assault,kernel="rectangular")D6=density(df$Assault,kernel="triangular")hist(df$Assault, main="DistribucionAsaltos-comparativo", freq=FALSE)lines(D1,lwd=2,lty=1,col="blue") lines(D2,lwd=2,lty=1,col="red")lines(D3,lwd=2,lty=1,col="green")lines(D4,lwd=2,lty=1,col="gray")lines(D5,lwd=2,lty=1,col="orange")lines(D6,lwd=2,lty=1,col="gold")
2.5.5 Construcción de Kernels
Para la construcción de funciones kernels, se debe considerar ciertas características geométricas y las propiedades de este tipo de funciones.
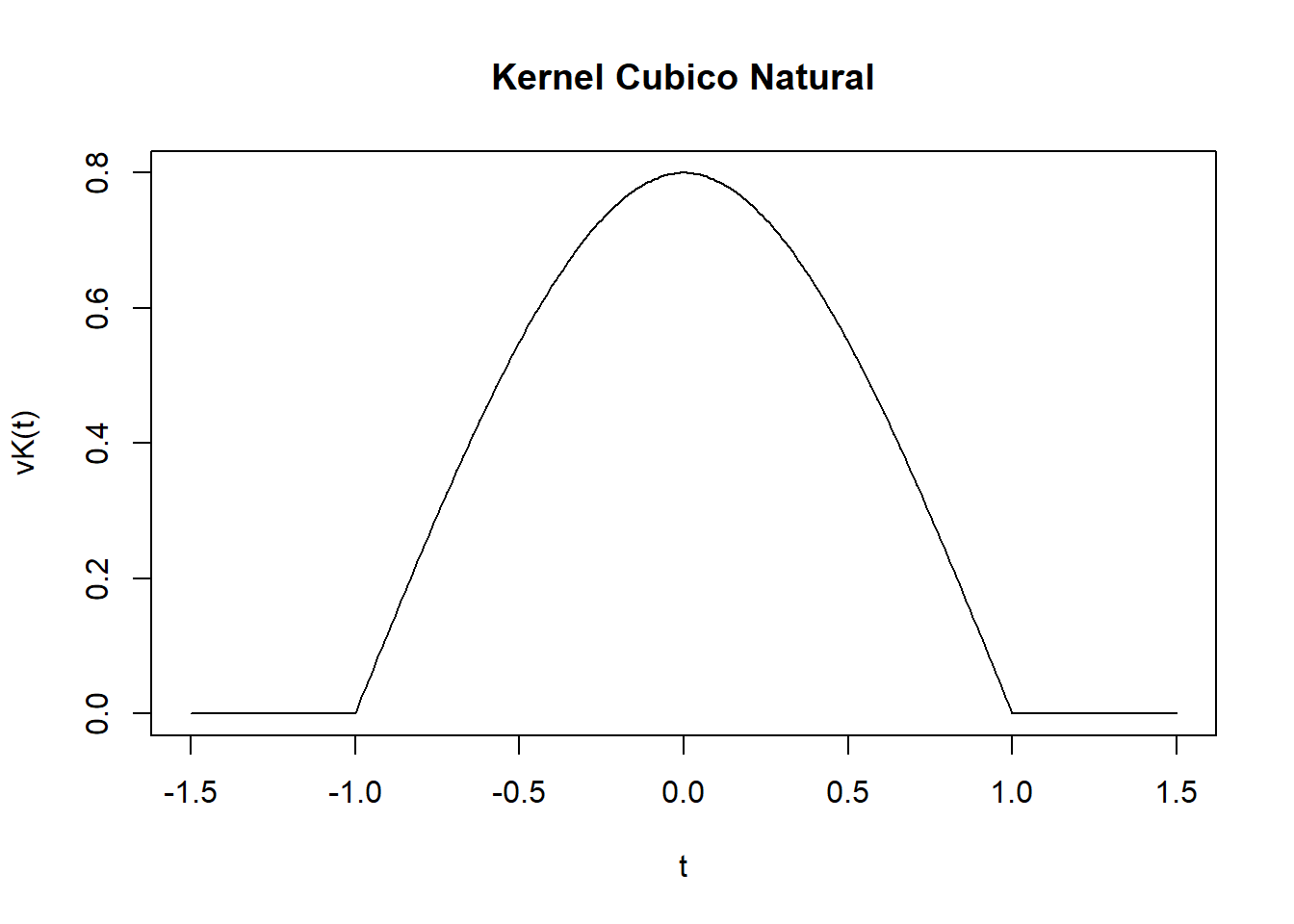
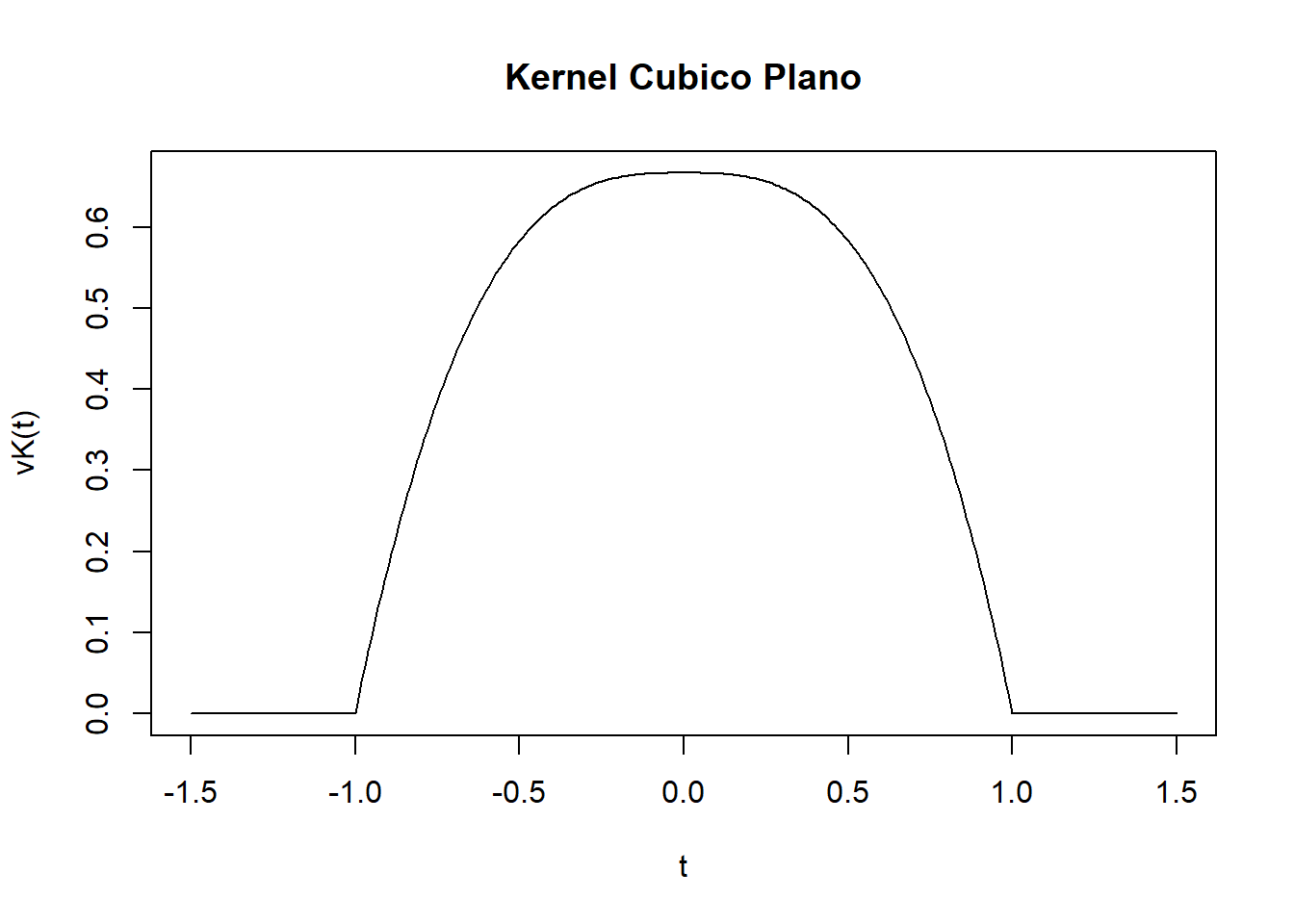
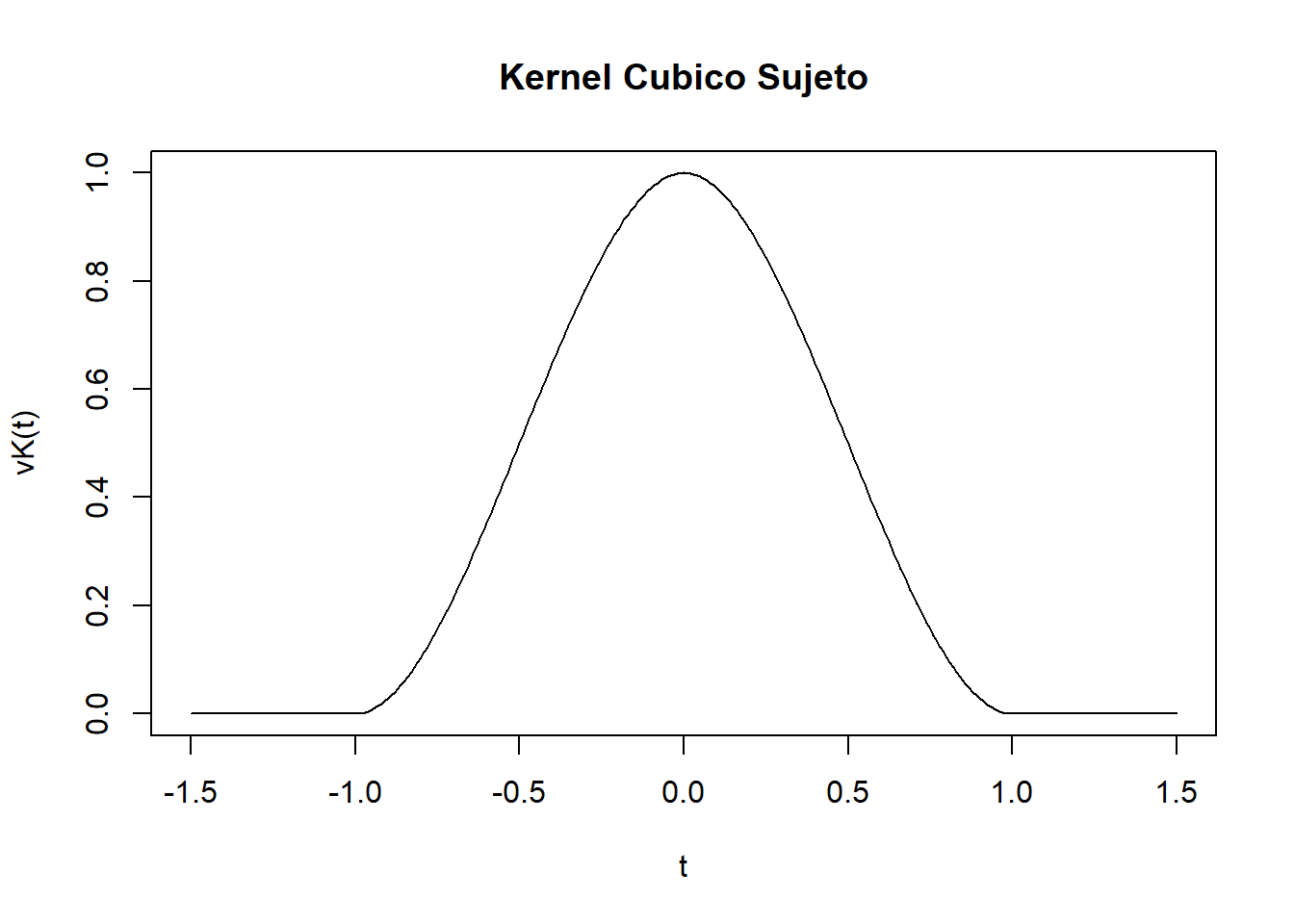
Kernel Cúbico Natural
En este ejemplo consideremos una función cúbica, definida entre \([-1,1]\) y 0 en otro caso, manteniendo la continuidad hasta la primera derivada con extremos libres sin curvaturas (\(K''(1)=K(-1)=0\)).
Estimaremos el polinomio cúbico \(K(x)=ax^3+bx^2+cx+d\) del tramo derecho (\(x \in [0,1]\)). Tenemos la siguientes derivadas:
\(K'(x)=3ax^2+2bx+c\)
\(K''(x)=6ax+2b\)
Tenemos las condiciones geométricas es decir:
\(K(1)=0 \Rightarrow a+b+c+d=0\), por continuidad de los Kernels
\(K'(0)=0 \Rightarrow c=0\), por el eje de simetría es un punto crítico.
\(K''(1)=0 \Rightarrow 3a+b=0\) por supuesto de la curvatura en los extremos.
Por otro lado, \(K(0)=d\) la altura de la densidad del Kernel. Esto implica que \(K(x)=\frac{d}{2}x^3-\frac{3d}{2}x^2+d\).
Para que \(K(x)\) sea una función de densidad se debe cumplir que:
Calcule los valores de a, b, c para que la función \(K(x)=bcos(ax)+c\),sea un kernel de densidad en el intervalo [-1,1] asumiendo que la segunda derivada en los extremos es nula (sin curvatura) y con \(b\neq 0\) y \(a \in ]0,\pi]\)
Calcule los valores de a, b, c para que la función \(K(x)=ax^2+bx+c\),sea un kernel de densidad en el intervalo [-1,1].
Calcule los valores de a, b, c para que la función \(K(x)=bcos(ax)+c\),sea un kernel de densidad en el intervalo [-1,1] asumiendo la unión con los extremos es suave y con \(b\neq 0\) y \(a \in ]0,\pi]\)
Sea \(x \in [x_1-h,x_N+h]\) una variable aleatoria con distribución \(\hat f(x)\). Demuestre que \(E[x]=\bar X\), para una m.a.s \(X=x_1,x_2,...,x_N\)
Ejercicio 1 página 325 del libro.(Capitulo 20) Wasserman (2006)
Dada una muestra aleatoria simple de la una variable aleatoria X, con los siguientes valores:
\[1 ,2.5 ,2.5 ,3,3, 3 ,4\] Usando un Kernel Triangular con bandwith de 1.5. Estime el valor de la función de densidad para los puntos 1.75, 2, 3.5
Repita el ejercicio anterior usando el Kernel Uniforme y Kernel Epanechnikov.
Rosenblatt, M. (1956). Remarks on Some Nonparametric Estimates of a Density Function. The Annals of Mathematical Statistics, 27(3), 832-837. https://doi.org/10.1214/aoms/1177728190