La simulación es una técnica de modelado que reproduce el comportamiento de un sistema real a lo largo del tiempo mediante un conjunto de ecuaciones y reglas lógicas, sin intervenir en el sistema físico. Por ejemplo, en 1949 Metropolis y Ulam desarrollaron el método de Monte Carlo en el Laboratorio Nacional de Los Álamos ( Metropolis & Ulam (1949) ).
Definición 5.1 Un sistema es un conjunto delimitado de componentes (entidades, variables o agentes) que interactúan entre sí según reglas bien definidas. Cada componente posee uno o varios estados internos que evolucionan en el tiempo como resultado de: 1. Su dinámica interna (las propias reglas de actualización de su estado). 2. Las interacciones con otros componentes. 3. Estímulos o perturbaciones externas.
El sistema dispone además de una frontera conceptual que delimita lo que está modelado (“dentro”) de lo que constituye el entorno (“fuera”), aunque este pueda influir a través de entradas y salidas.
Para mayores referencias de esta sección se puede consultar Banks et al. (2010)
Pensiones
Componentes
Cotizantes activos: trabajadores que aportan cada periodo.
Pensionados: beneficiarios que reciben pago de pensión.
Fondo de reserva: acumulado de recursos financieros.
Estados internos
cantidad y monto de cuotas realizadas por cada cotizante (cuenta).
Nivel de reserva en el fondo.
Reglas de transición
Contribución: cada cotizante aporta un porcentaje de su salario, que incrementa su cuenta y la reserva del fondo.
Retiro: al alcanzar la edad y/o requisitos, un cotizante pasa a pensionado y comienza a recibir una renta vitalicia (pago de pensión).
Rendimientos: la reserva del fondo crece a la tasa de interés pactada.
Mortalidad: aplicación de tablas de vida para determinar decrecimiento de la población de cotizantes/pensionados.
entre otros.
Interacciones
Los aportes de los cotizantes financian el fondo de reserva, que a su vez paga las pensiones de quienes ya se retiraron.
Estimulación externa
Tasa de interés de mercado (afecta el rendimiento).
Cambios demográficos (variaciones en la tasa de natalidad, esperanza de vida).
Política pública (ajuste de tasas de cotización, edad de jubilación, leyes).
Frontera
Está modelado todo lo que ocurre dentro del esquema de pensiones administrado (aportes, pagos, inversiones).
Fuera quedan otras dinámicas macro (PIB, empleo total, inflación), que se incorporan sólo como inputs (tasa de interés, crecimiento salarial, hipótesis demográficas).
Mercado de Bienes
Componentes
Consumidores: con presupuestos y preferencias.
Productores: con funciones de producción y costes.
Precio del bien: variable que equilibra oferta y demanda.
Estados internos
Riqueza o ingreso disponible de cada consumidor.
Inventario y capacidad productiva de cada empresa.
Reglas de transición
Decisión de consumo: cada consumidor asigna su ingreso entre bienes y ahorro según su función de utilidad.
Decisión de producción: cada empresa ajusta producción para maximizar beneficios, dadas las expectativas de precio.
Ajuste de precios: el precio sube cuando la demanda excede la oferta y baja en la situación opuesta.
Interacciones
La demanda agregada de consumidores determina el precio, que a su vez influye en la oferta de productores.
El ahorro de los consumidores puede financiar la inversión de las empresas.
Estimulación externa
Política monetaria: variaciones en la tasa de interés afectan el costo del crédito y la demanda.
Choques de oferta: cambios en costes de insumos o en tecnología.
Frontera
Dentro: La oferta, la demanda y el ajuste de precio del bien en estudio.
Fuera: otras partes de la economía (mercado laboral, sector financiero) que influyen sólo a través de las variables de estímulo (tasa de interés, coste de factores).
Los sistema lo podemos clasifica en:
Sistema Simple o analítico, donde su comportamiento global es predecible a partir de sus componentes, los componentes tienen correlaciones lineales altas. Sistema Complejos o estocásticos Son modelos multiescala, es decir varían con el tiempo, las interacciones de los componentes tienen a no ser lineales.
Para modelar cada sistema se puede usar metodologías analíticas, pero principalmente para los sistemas simples. Algunos métodos analíticos son: Ecuaciones diferenciales, transformadas, Cadenas de Markov con estados discretos y finitos, análisis espectral, análisis de autovalores, teoría de colas clásica, integración de funciones de supervivencia, modelos lineales generalizados, entre otros.
Definición 5.2 La simulación es la construcción de un modelo abstracto que represente algún sistema de la vida real, con la descripción a través del tiempo, por medio de una serie de ecuaciones y relaciones entre las variables.
Los procesos de simulación generalmente se realizan a través de un programa de computadora.
La simulación es una técnica ampliamente utilizada para el análisis y estudios de sistemas complejos, dado que los métodos análiticos puede utilizar un número importante de suposiciones (simplificaciones) del sistema, lo que ocasiona que la solución obtenida no se aproxime a la realidad, por omisiones en la sinergias entre los componentes del sistema lo que genera un sesgo grande.
El principal problema con los procesos de simulación es su costo computacional, que tienen a ser elevado.
5.1.1 Modelos Determinísticos
Los métodos analíticos, son llamados también modelos determinísticos, los cuales tiene la siguientes características:
Son fáciles de diseñar, implementar y comprender.
Tiene un costo computacional bajo, es decir rápidos y de poco consumo de recursos.
Para generar otras respuestas, es deben construir escenarios de estrés o análisis de sensibilidad, usualmente llamados pesimita y optimista.
Suelen ser una simplificación muy general de los sistemas complejos lo que puede ignorar variabilidades significativas de las variables.
5.1.2 Modelos Estocásticos
Los modelos estocásticos, tienen las siguientes características:
Son más dificiles de diseñar, implementar y comprender.
Tiene costos computacionales altos.
Son más flexibles ya que pueden captar complejidades en los sistemas.
Se suele generar muchos escenarios.
suelen ser más realista.
La escogencia entre un modelo y otro depende de multiples factores como: * La naturaleza del problema. * La cantidad y calidad de los datos. * Los objetivos del modelo, que queremos modelar. * Las limitaciones del modelo.
Lo modelos determinísticos se concentran más en la respuesta esperada y los modelos estocásticos se concentran más en un rango razonable de respuestas y sus riesgo, en la distribución de la respuesta
Comparación de Modelos
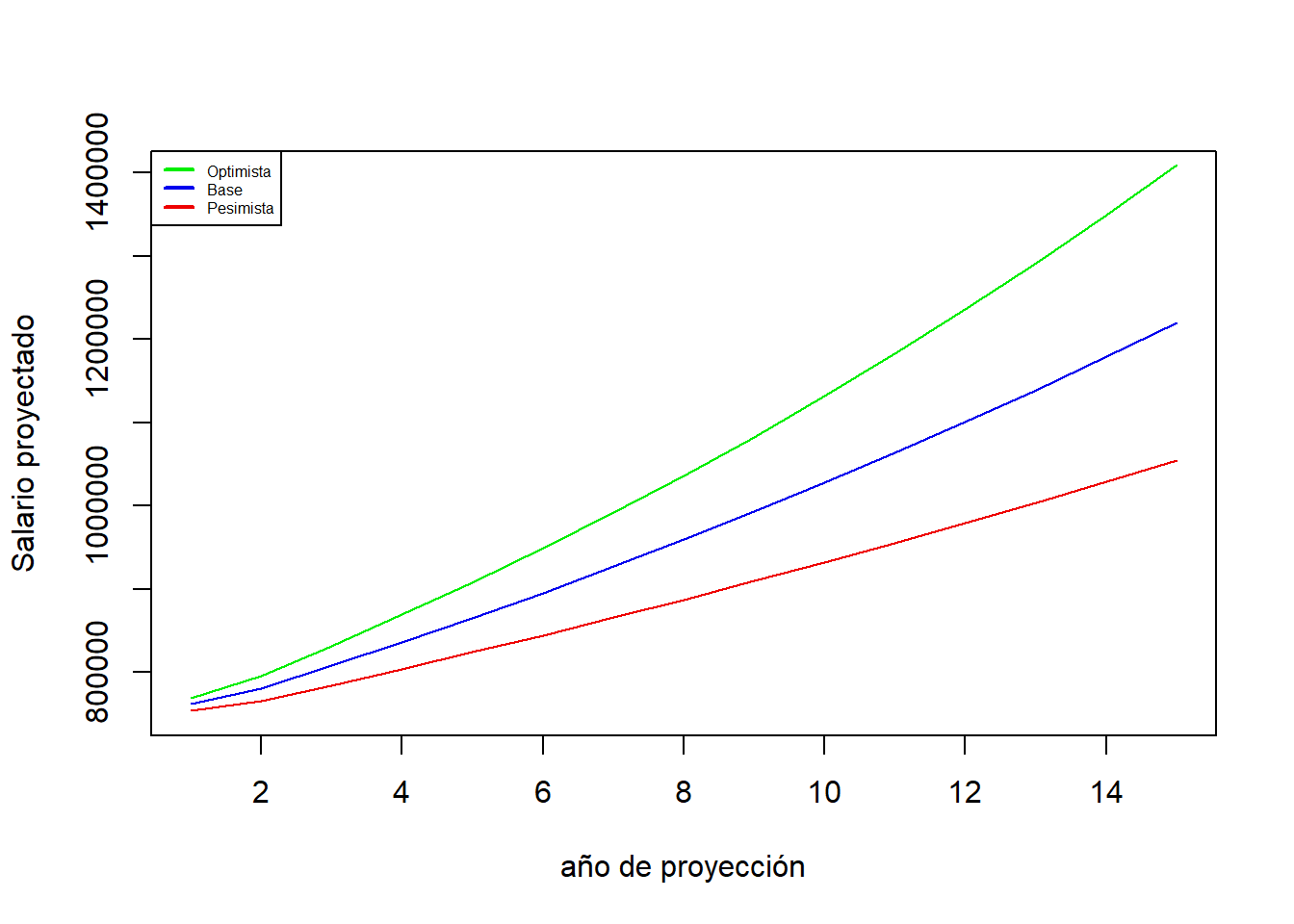
Se quiere proyectar el salario de una persona en 15 años. El actuario considera que la persona se le incrementará el salario igual a la inflación de 1% para el primer año, 2% para el segundo año y 3% para el resto de periodos de proyección, más un 0.5% por promociones o ascensos. Con un salario inicial de 750 000 colones
rate<-rep(0.035,15) # se crea las tasas de incremento salarialrate[1]<-0.015rate[2]<-0.025Acum<-1+rateAcum<-cumprod(Acum)Sal_ini=750000Sal_proy<-Sal_ini*Acum#Pesimista Se rebaja la inflación 1%ratep<-rep(0.025,15)ratep[1]<-0.005ratep[2]<-0.015Acump<-1+ratepAcump<-cumprod(Acump)Sal_proyp<-Sal_ini*Acump#Optimista Se sube la inflación 2%rateo<-rep(0.045,15)rateo[1]<-0.025rateo[2]<-0.035Acumo<-1+rateoAcumo<-cumprod(Acumo)#plot(Acumo)Sal_proyo<-Sal_ini*Acumoplot(Sal_proy, type="l", ylab="Salario proyectado",xlab="año de proyección",col="blue2",ylim=c(750000,1400000))lines(Sal_proyp, type="l", col="red2")lines(Sal_proyo, type="l", col="green2")legend(x="topleft",legend=c("Optimista","Base","Pesimista"),col=c("green2","blue2","red2"),lty=c(1,1,1),lwd=2,cex=0.5)
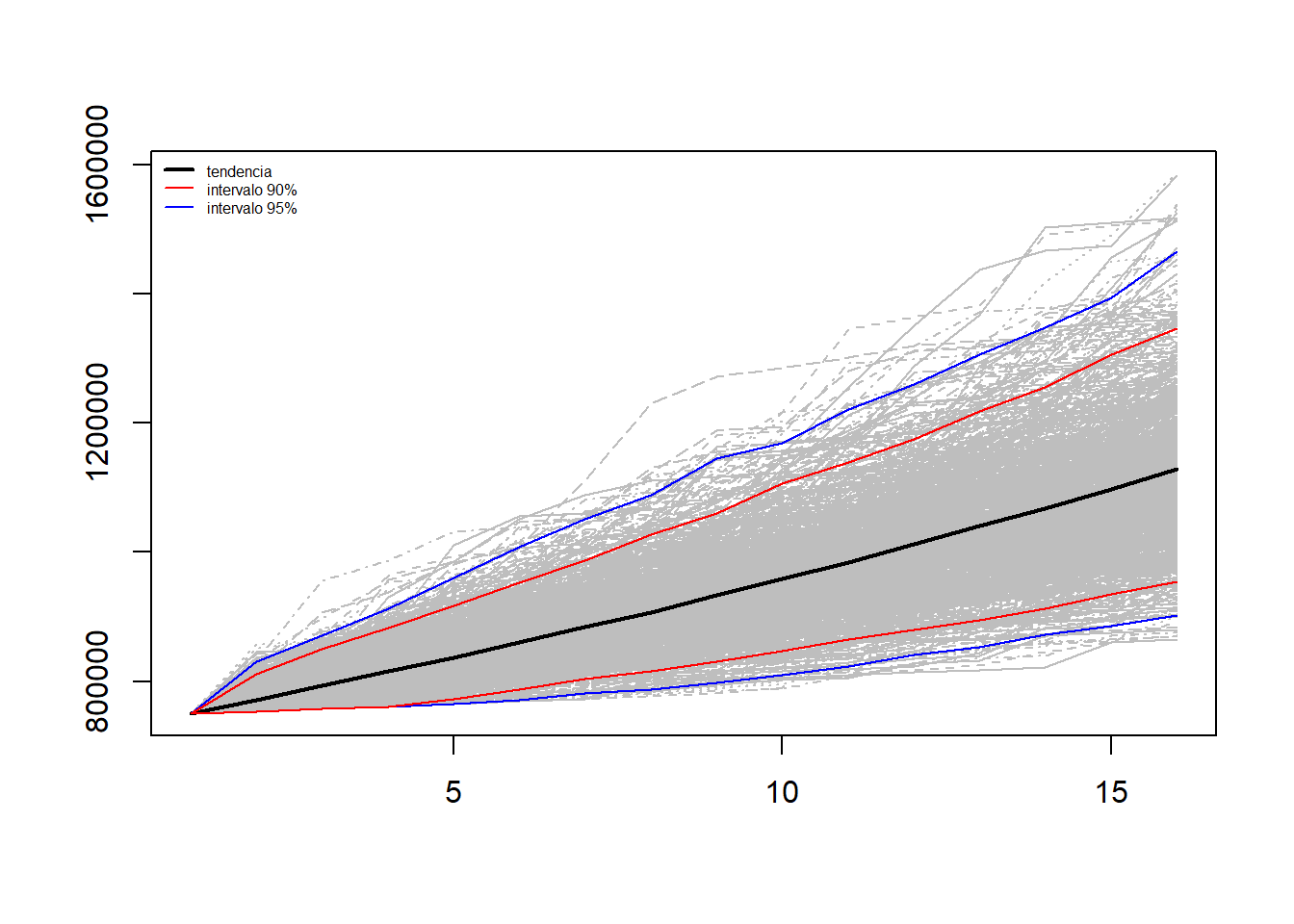
Por otro lado, otro actuario considera que considerar la inflación de los 2 últimos años, y se obtiene que el promedio la inflación ha estado entre 0,75% con una varianza del 13.95, considera que los incrementos se comportan log normalmente, y que el comportamiento de ascensos y promociones es de un 0,5%. Con el salario inicial, realiza 1000 escenarios
Recordemos que para una v.a. \(X\sim U(a,b)\), los eventos tiene la misma probabilidad de salir, no existe unos datos con mayor probabilidad de ocurrencia.
Para eventos discretos, donde existen \(n\) eventos posibles, tenemos que:
\[P(X=x_i)=\frac{1}{n}, \; x_i=1,\dots,n\] Para eventos continuos, se utiliza la densidad de una \(U(0,1)\), por lo que
\[f(x)=1, \; \text{si } x \in [0,1]\] La escogencia de una distribución uniforme, \(U(0,1)\), radica que la mayoría de procesadores, generan números pseudoaleatorios con distribución uniforme continua, más adelante veremos como obtener estos números.
Por la propiedad de la distribución uniforme, tenemos que: \(P(X\leq x_i)=x_i\), esto nos permite “discretizarla”,asignando valores a los diferentes resultados, por medio de un proceso que se llama transformada inversa para variables discretas
Sea \(X\sim F(x)\) discreta que toma valores \(\{x_1,x_2,...,x_n\}\). Para generar una muestra de \(k\) elementos de \(X\) seguimos el siguiente algoritmo:
Se generar \(u_1 \sim U[0,1]\) y se toma \(k=k-1\)
Se determina el entero \(I\) más pequeño que satisface que \(u_i\leq F(x_I)\)
Retorna \(y_i = x_I\)
Se retorna k veces al paso 1.
Generación de números discretos
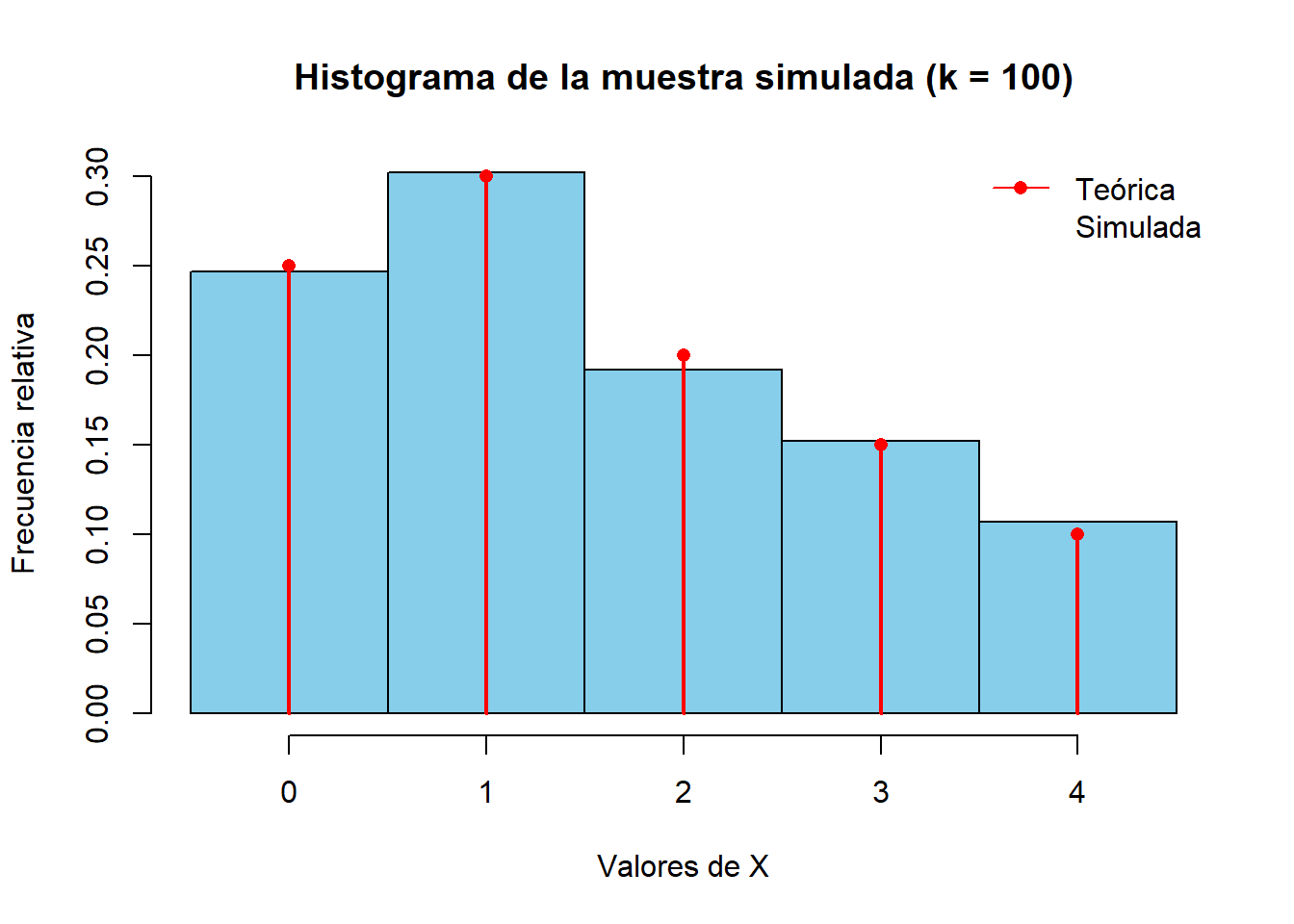
Un supermercado, realiza un estudio sobre la cantidad de personas que en un minuto en específico estén en fila para ser atendidos en una caja. Ellos determinaron la siguientes probabilidades:
Clientes
Probabilidad
0
0,25
1
0,30
2
0,20
3
0,15
4
0,10
Ahora quieren generar una simulación 1000 casos, con el siguiente resultado
# Definición de la distribución discretax <-0:4p <-c(0.25, 0.30, 0.20, 0.15, 0.10)Fx <-cumsum(p) # Función de distribución acumulada# Tamaño de la muestrak <-1000# Generación de la muestra por el método de la inversaset.seed(2025) #Semilla para simulacionesu <-runif(k)y <-sapply(u, function(ui) { x[ which(ui <= Fx)[1] ]})# Histograma de la muestra simuladahist(y,breaks =seq(min(x) -0.5, max(x) +0.5, by =1),freq =FALSE,col ="skyblue",main ="Histograma de la muestra simulada (k = 100)",xlab ="Valores de X",ylab ="Frecuencia relativa")# La distribución teórica para compararpoints(x, p, col ="red", pch =16)lines(x, p, type ="h", col ="red", lwd =2)legend("topright",legend =c("Teórica", "Simulada"),col =c("red", "skyblue"),pch =c(16, NA),lty =c(1, NA),pt.cex =c(1, NA),bty ="n")
Para el caso de la generación de números aleatorios continuos, usamos el mismo algoritmo, pero usando la función inversa de la distribución a simular
Se generar \(u_1 \sim U[0,1]\) y se toma \(k=k-1\)
Retorna \(y_i = F^{-1}(u_i)\)
Se retorna k veces al paso 1.
Esto este algoritmo y el anterior se justifican como un procedimiento del Teorema de la Transforma de la Distribución.
Teorema 5.1Teorema de la transforma de la distribución Sea \(X\) una v.a. continua con función de distribución \(F(x)=P(X\leq x)\) y sea \(U\sim U(0,1)\). Definimos: \[Y=F^{-1}(U)\]
Entonces para cualquier \(x\) se cumple:
\[P(Y \leq x)=P(F^{-1}(U)\leq x)=P(U \leq F(x))=F(x)\] ya que \(U\) es uniforme. Por lo tanto \(Y\) tiene la misma distribución que \(X\).
Los programas de computo más robustos, tiene programado la generación de números aleatorios con las distribuciones más utilizadas.
5.1.4 Generación de números pseudoaleatorios
Como observamos, la generación de números aleatorios depende que podamos tener una muestra de números aleatorios con distribución Uniforme, sin embargo obtener estos números en la realidad y capturados suelen ser procesos muy complicados. Algunos métodos para obtener números aleatorios uniformes son:
Tablas de números aleatorios, documentos con números aleatorios previamente muestreados.
Generados en la vida real, por ejemplo con base en la interrupción de un circuito en la computadora, o resultado de un proceso uniforme, como por ejemplo los números que sale en una tómbola o ruleta.
Este último método, tiene la particularidad que no es repetible, es decir no se puede volver a generar la misma secuencia de números uniformes, por lo que hay que registrarlos.
Por lo que, otra solución es recurrir a un algoritmos o métodos para encontrar una secuencia de números que tenga una distribución similar a la Uniforme, estos números son llamados números pseudoaleatorios.
Método de Centros de Cuadrados
Este primer método para generar pseudoaleatorio, fue propuesto por Neumann (1951), se basa en tomar un número elevarlo al cuadrado y tomar los dígitos del centro como nuevo número, luego repetir el proceso, por ejemplo:
\[2061 \rightarrow 4247721\rightarrow 2477 \rightarrow 6135529\rightarrow1355 \rightarrow \cdots \] La desventaja de este método es que las secuencia de número pueden ser cortas y caer un repetición de ciertos números.
El caso anterior, luego de 34 números generados termina en 0. si se toma el número 2500 como semilla para el proceso, se repite el 2500 desde la primera iteración. A pesar de esto, hay secuencia de número que pueden generar más de 100 000 números diferentes.
Método Congruencia Lineal
Este otro método fue propuesto por Lehmer (1951), y es el método usado por lo generar en los programas, y se basa en la siguiente fórmula recurrente:
\[Z_i=(A(Z_{i-1})+C)\text{mod } M\] Se puede demostrar por inducción que:
Este método tiene como ventaja que sólo hay que guardar la semilla \(Z_0\) para generar la secuencia.
La elección de los valores \(A,C\) y \(M\) como la semilla \(Z_0\) impactan la velocidad de generación y el largo de la secuencia.
Se tiene que \(\frac{Z_i}{M} \in [0,1]\) y el largo del período de la secuencia a generar será menor o igual a M.
5.2 Procesos de Markov
Una cadena de Markov es un tipo especial de proceso estocástico discreto en el que la probabilidad de que ocurra un evento depende solamente del evento inmediatamente anterior, este parte del capitulo se tomo de Grinstead & Snell (1997) y Ross (2014).
Los eventos independientes no poseen memoria anterior, es decir el resultado que \(X_{n+1} = j\) depende únicamente del valor actual de \(X_n\), la propiedad que dependa del estado actual se le conoce como propiedad de Markov, esta propiedad la podemos escribir de la siguiente manera:
Definición 5.3Cadena de Markov
Una Cadena de Markov es un proceso estocástico a tiempo discreto \(\{ X_n:n=0,1,2,...\}\) con un espacio de estados discretos \(S\) para cualquier entero \(n \geq 0\) u cualquier \(x_0,x_1,x_2,....,x_{n+1} \in S\) que cumple que:
Las cadenas de Markov, son a honor de Andrei Markov (1856-1922).
Ejemplo 5.1Caminata Aleatoria
Consideremos una persona que realiza un camino aleatorio sobre los número enteros, que forman el espacio de estados. Para cada unidad de tiempo la persona que se encuentra en el punto \(i\) da un paso hacia adelante (\(i+1\)) o hacia atrás (\(i-1\)) con probabilidades respectivas \(p\) y \(1-p\).
Ejemplo 5.2El problema de Marketing
En un pueblo sólo existen dos cafeterías: \(A\) y \(B\). Cada habitante visita alguna de las dos cafeterías al día. Un estudio de marketing revela que una persona fue a la cafetería \(A\) al día siguiente visita la cafetería \(B\) con una probabilidad de \(\alpha\). Por otro lado una persona que fue a la cafetería \(B\) cambia de cafetería con probabilidad (\(\beta\)). Podemos plantear las siguientes preguntas:
¿Cuál es la probabilidad de que una persona que fue hoy a la cafetería \(A\) tarde \(n\) días en regresar?
¿Cuál es la proporción de clientes que esperarían a largo plazo tener cada cafetería?
Definición 5.4Probabilidad de Transición
Se dice que \(p_{ij}=P[X_{n+1}=j|X_n=i]\) la probabilidad que el proceso estocástico o cadena de Markov pase del estado \(i\) al estado \(j\), y se denomina probabilidad de transición entre los estados \(i\) y \(j\), si esta probabilidad no depende del tiempo \(n\) se denomina Homogénea a la Cadena de Markov.
En particular para un estado \(i\) fijo la suma de todas las probabilidades de transición es 1.
\[p_{ij}=\sum_{j}p_{ij}=1\]
Definición 5.5Matriz de Transición
La matriz formada por las probabilidades de transición \(p_{ij}\) se le llama matriz de transición de un paso:
\[
P=\begin{pmatrix}
p_{00} & p_{01} & \cdots \\
p_{10} & p_{11} & \cdots \\
\vdots & \vdots & \vdots
\end{pmatrix}
\] Si \(P\) es llamada matriz estocástica y una de sus principales características es que tiene elementos no negativos y que la suma de todos los elementos de cada fila es 1.
Ejemplo 5.3Continuación: El problema de Marketing
Del problema del marketing tenemos la siguiente matriz de transición de un paso:
Para estimar la probabilidad que una Cadena de Markov, pase del estado \(i\) al estado \(j\) en \(n\) pasos, se denota por \(p^n_{ij}\) y cumple que es la entrada \(ij\) de la matriz \(P^n\).
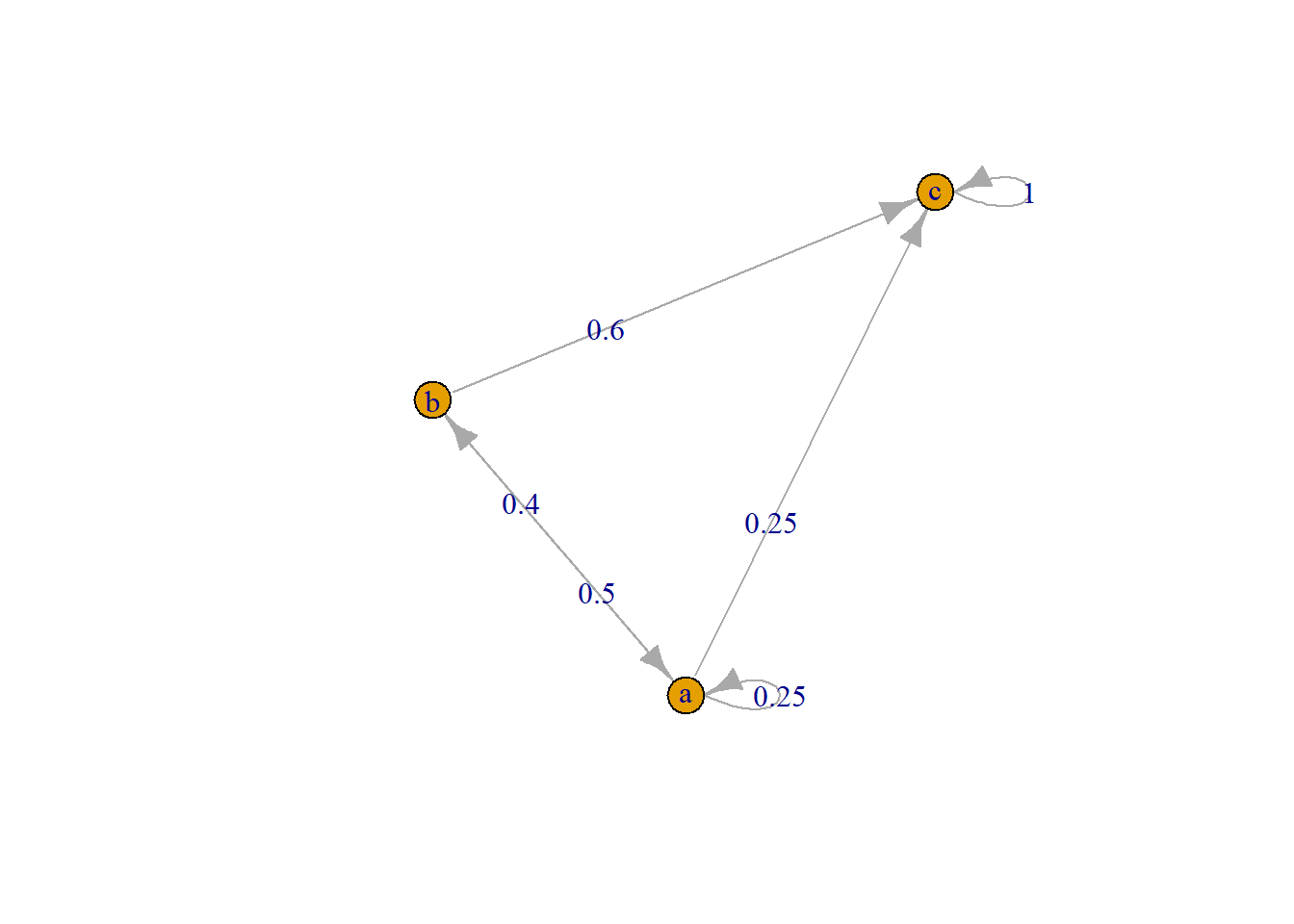
Cadena 1
A 3 - dimensional discrete Markov Chain defined by the following states:
a, b, c
The transition matrix (by rows) is defined as follows:
a b c
a 0.25 0.5 0.25
b 0.40 0.0 0.60
c 0.00 0.0 1.00
plot(mc)
5.3 Clasificación de Estados:
Se dice que el estado \(j\) es alcanzable desde el estado \(i\) si existe un \(p^n_{ij}>0\), para algún \(0 \leq n <\infty\).
Si es estado \(i\) es alcanzable desde el estado \(j\) y el estado \(j\) es alcanzable desde el estado \(i\), se dice que se comunican
Si ningún estado \(j\) con \(j \neq i\), es alcanzable desde el estado \(i\) se dice que es un estado absorbente
Si dos estados \(i\) y \(j\) se comunican se dice que están en la misma clase.
Una cadena de Markov se dice que es irreducible si todos los estados pertenecen a la misma clase, es decir todos se comunican entre si.
Una clase \(C\) se dice cerrada si para cualquier estado \(i \in C\) y cualquier estado \(j \notin C\), se tiene que \(p_{ij}=0\), es decir que cualquier estado dentro de \(C\) no se puede alcanzar ningún estado fuera de \(C\).
Si para cualquier estado \(i\) la probabilidad que empezando en el estado \(i\), retorne al estado \(i\), es decir que \(p^n_{ii} \neq 0\) para algún \(n>0\) se dice que es recurrente y si no se dice que es transitorio
Utilizando el paquete markovchain, este tiene otras funciones que podemos utilizar que son:
absorbingStates: Que identifica los estados absorbentes.
transientStates: Que identifica los estados transitorios.
recurrentClasses: Que identifica las clases recurrentes.
cat("Clases recurrentes: \n" )
Clases recurrentes:
recurrentClasses(mc)
[[1]]
[1] "c"
cat("Estados transitorios: \n" )
Estados transitorios:
transientStates(mc)
[1] "a" "b"
cat("Estados absorbentes: \n" )
Estados absorbentes:
absorbingStates(mc)
[1] "c"
Uso del paquete Markovchain
Usaremos los datos de una ciudad desconocida donde llueve \(n\) número de veces a la semana.
Como se puede observar, según las 1096 observaciones, 548 semanas no ha llovido ningún día, 295 veces de 1 a 5 veces y 253 más de 6 veces.
Construiremos un modelo para una Cadena de Markov, con esos tres estados. Para esto debemos definir una variable que contenga los estados en secuencia.
PE <- rain$rain
Con la función “createSequenceMatrix”, podemos crear una matriz de secuencias (observada)
(P1 <-createSequenceMatrix(PE))
0 1-5 6+
0 362 126 60
1-5 136 90 68
6+ 50 79 124
Con la función markovchainFit() podemos estimar la matriz de transición con base en los datos, por medio del método de máxima verosimilitud, dado un nivel de confianza.
$estimate
MLE Fit
A 3 - dimensional discrete Markov Chain defined by the following states:
0, 1-5, 6+
The transition matrix (by rows) is defined as follows:
0 1-5 6+
0 0.6605839 0.2299270 0.1094891
1-5 0.4625850 0.3061224 0.2312925
6+ 0.1976285 0.3122530 0.4901186
$standardError
0 1-5 6+
0 0.03471952 0.02048353 0.01413498
1-5 0.03966634 0.03226814 0.02804834
6+ 0.02794888 0.03513120 0.04401395
$confidenceLevel
[1] 0.95
$lowerEndpointMatrix
0 1-5 6+
0 0.5925349 0.1897800 0.0817850
1-5 0.3848404 0.2428780 0.1763188
6+ 0.1428496 0.2433971 0.4038528
$upperEndpointMatrix
0 1-5 6+
0 0.7286330 0.2700740 0.1371931
1-5 0.5403296 0.3693669 0.2862663
6+ 0.2524073 0.3811089 0.5763843
$logLikelihood
[1] -1040.419
Como se observa esta función markovchainFit, nos brinda como resultado una matriz de transición esperada, calcula el error estándar para cada probabilidad de transición y su intervalo de confianza.
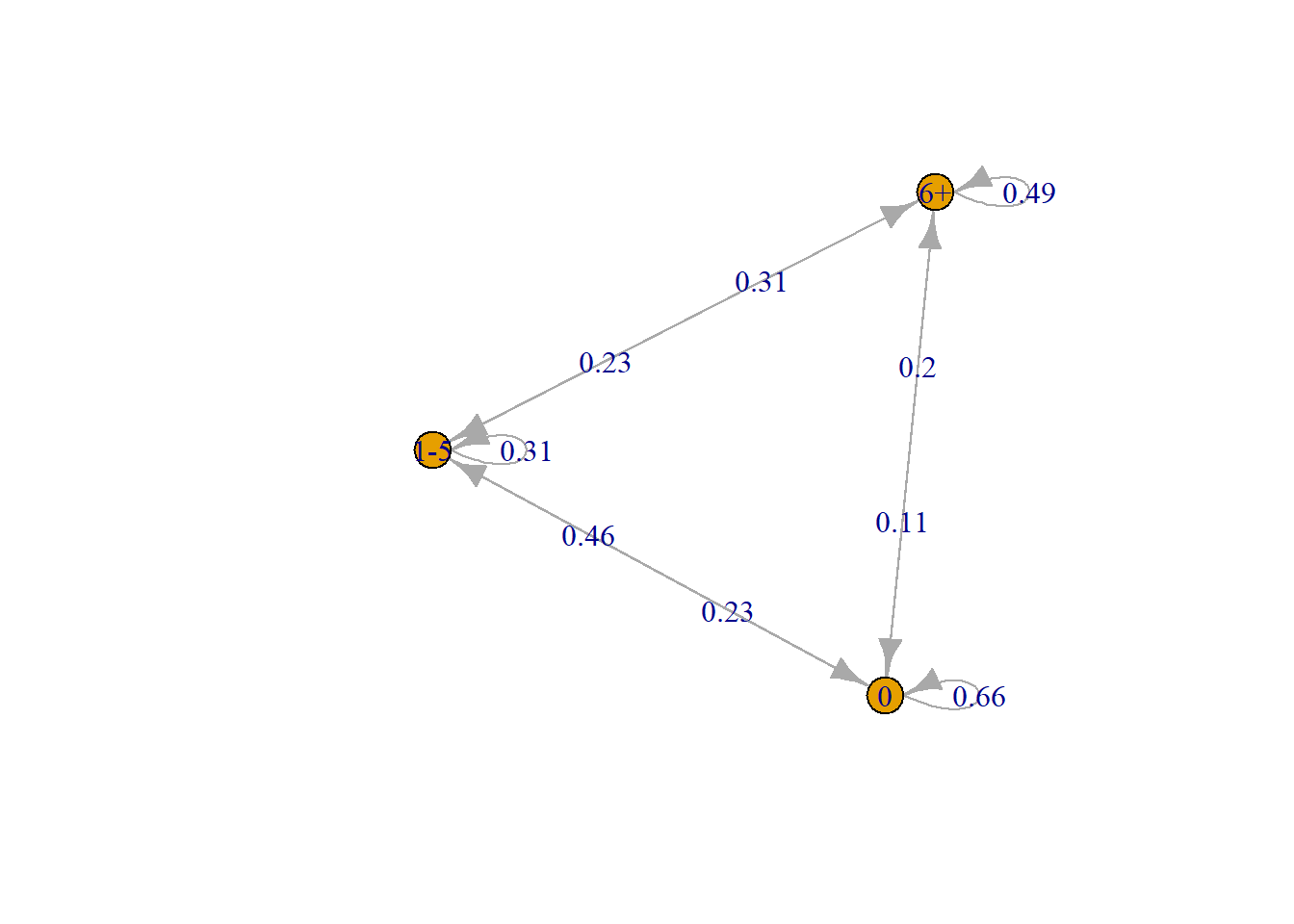
Podemos graficar la cadena esperada
plot(Fit$estimate)
Definición 5.6Distribución Estacionaria
Dada una cadena de Markov con número de estados finitos y un vector:
\[\pi=(\pi_0,\pi_1,...,\pi_{n-1})\] se dice que es una distribución estacionaria de la cadena de Markov si:
\(\pi_i \geq 0\) para cualquier \(i\).
\(\sum_{i=0}^{n-1}\pi_i=1\)
\(\pi P=\pi\)
Para hallar la distribución estacionaria de la matriz podemos usar la función steadyStates
steadyStates(Fit$estimate)
0 1-5 6+
[1,] 0.5008871 0.2693656 0.2297473
5.4 Introducción a las Cadenas de Markov por Montecarlo
Desarrollaremos una aplicación de la Distribución de la Esperanza de Vida, para lo cual introduciremos el concepto de Cadena de Markov por Monte Carlo(MCMC), que consiste en generar o simular \(N\) veces una cadena de Markov y con sus resultados realizar inferencias estadísticas.
5.5 Aplicación: Distribución Esperanza de Vida
Tomaremos con una Cadena de Markov simple, las probabilidades de fallecimiento de una persona de edad 0. Con los cálculos actuariales tradicionales, podemos obtener la Esperanza de Vida de esa persona, sin embargo, encontrar la distribución de las Edades de fallecimiento para la población de edad 0, se torna más complicado.
Por lo que podemos simular por medio de varias Cadenas de Markov, las distintas edades de fallecimiento, y con esto podemos realizar estimaciones inferenciales como el obtener un intervalo de confianza para la Esperanza de Vida, entre otras.
Por ejemplo estimar esta distribución, nos permitiría también estimar distribuciones de las anualidades.
Construiremos con base en la tabla de mortalidad, la esperanza de vida para una persona de edad 0, esto nos da como resultado 86.17065 años.
library(readxl)qxCero <-read_excel("C:/Users/Usuario/Downloads/qxCero.xlsx", sheet ="Hoja1")px=qxCeropx$qx=1-qxCero$qxcat("Esperanza de Vida, valor esperado: \n")
Esperanza de Vida, valor esperado:
(ex<-sum(cumprod(px$qx[2:116]))+0.5) #factor 0.5 es para estimar la esperanza continua.
[1] 86.17065
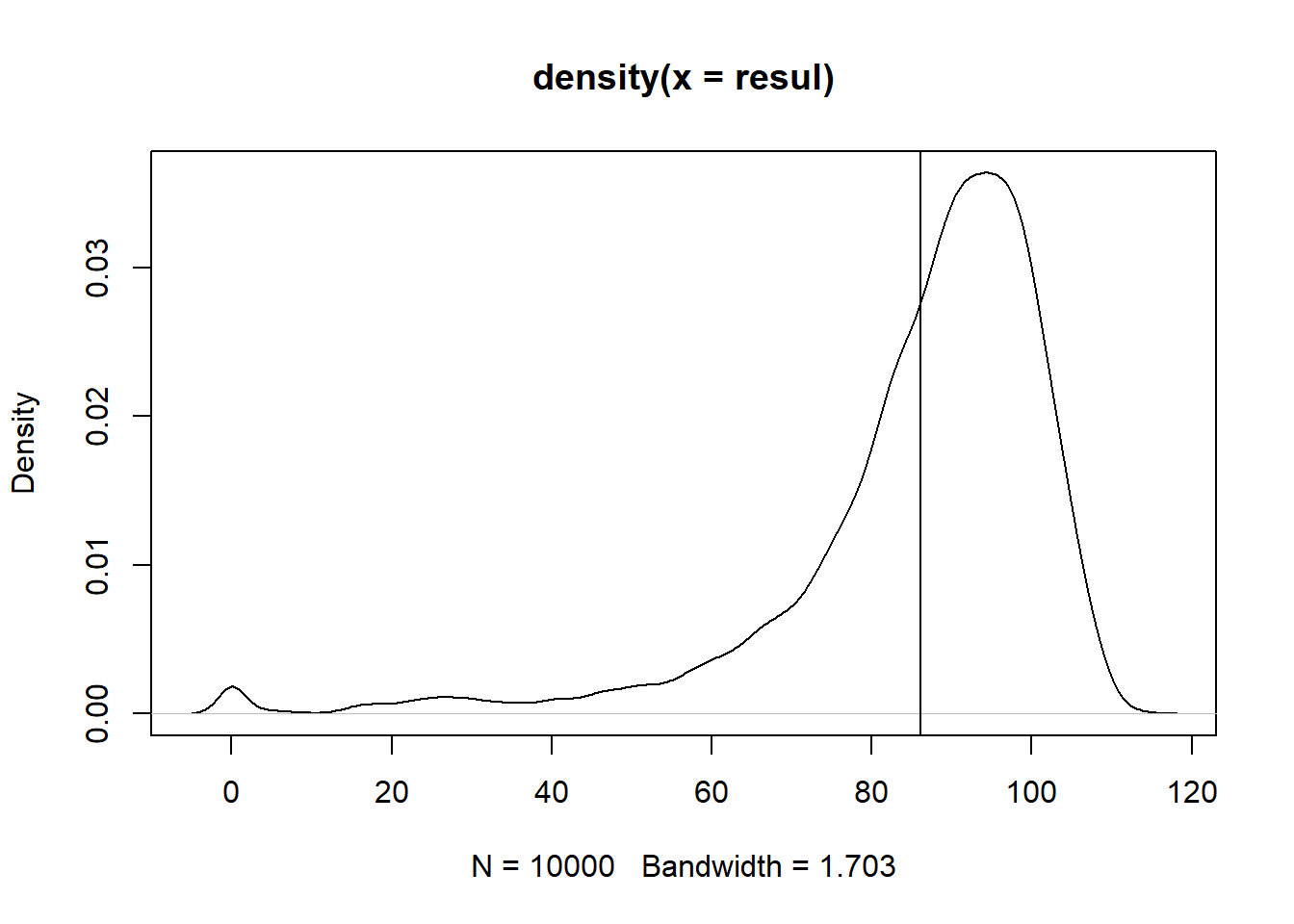
Realizaremos el proceso de Markov, para \(N= 10\^4\) casos y estimaremos el promedio de los resultados para cada cadena generada, este es el proceso conocimo como MCMC.
Este proceso como se observa, nos permite construir una curva de densidad y estimando la esperanza muestral nos da como resultado 86.4769 años de esperanza de vida, como observamos existe un diferencia con la estimación tradicional, esto producto del error de estimación, que podemos calcular de la siguiente manera:
cat("error absoluto: \n")
error absoluto:
(e1<-abs(emc-ex))
[1] 0.1314465
cat("error estandar: \n")
error estandar:
(e2<-sd(resul)/length(resul))
[1] 0.001726904
Para construir un intervalo de confianza para la Esperanza de Vida, podemos hacer un bootstrap con los datos del MCMC y estimar el intervalo con los diferentes métodos ya estudiados en el Capítulo 2.
Los resultados nos da, el valor original de esperanza muestral de 86.4769 el sesgo \(b_{boot}=0.0039829\) y la desviación estándar \(\sigma_{boot}=0.1596954\) y estimamos el promedio nos da el estimador bootstrap de la esperanza de vida que sería de 86.48088 años. Teniendo estos datos podemos estimar los intervalos de confianza según la metodología que consideremos:
Intervalos de Percentiles
En este caso, usaremos los percentiles \(0.0254\) y \(0.975\) para estimar un intervalo de confianza de 95%, según Ecuación 3.4. Para esto podemos usar la función boot.ci con type = “perc” o la función quantile, observe que ambos métodos nos dan el mismo resultado de \((86.18, 86.80)\), en este caso el valor estimado directamente por la tablas de mortalidad quedaría fuera del intervalo de confianza estimado (\(86.17\)).
cat("Intervalo de confianza-percentiles: \n")
Intervalo de confianza-percentiles:
boot.ci(results, conf=0.95, type="perc")
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = results, conf = 0.95, type = "perc")
Intervals :
Level Percentile
95% (85.70, 86.37 )
Calculations and Intervals on Original Scale
cat("Intervalo de confianza-percentiles funcion quantile: \n")
Intervalo de confianza-percentiles funcion quantile:
quantile(results$t, c(0.025, 0.975))
2.5% 97.5%
85.70436 86.36893
Si estimamos el intervalo de confianza bajo la metodología Normal, es decir usando como pivote una distribución normal, según Ecuación 3.2, con un nivel del 95%, el intervalo sería \((86.16, 86.79)\).
Nota La función boot.ci también puede estimar intervalos usando una distribución t-student como pivote.
cat("Intervalo de confianza-Normal: \n")
Intervalo de confianza-Normal:
boot.ci(results, conf=0.95, type="norm")
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = results, conf = 0.95, type = "norm")
Intervals :
Level Normal
95% (85.71, 86.36 )
Calculations and Intervals on Original Scale
#se puede usar student.
Como tercera opción tenemos el intervalo de confianza Pivotal, según Ecuación 3.3, que nos da como resultado el intervalo de confianza al 95% entre \((86.16,86.77)\)
cat("Intervalo de boot: \n")
Intervalo de boot:
boot.ci(results, conf=0.95, type="basic")
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = results, conf = 0.95, type = "basic")
Intervals :
Level Basic
95% (85.70, 86.38 )
Calculations and Intervals on Original Scale
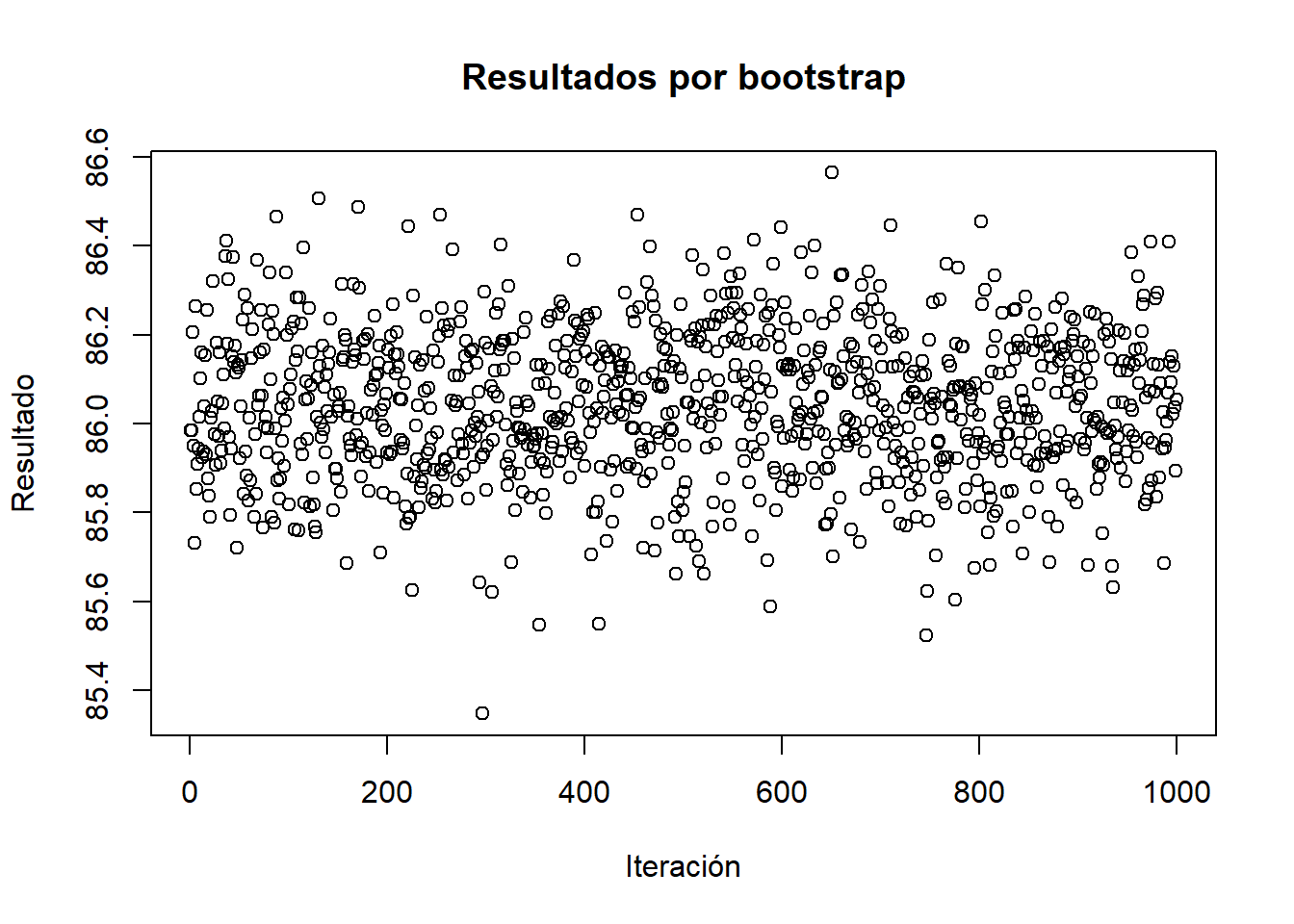
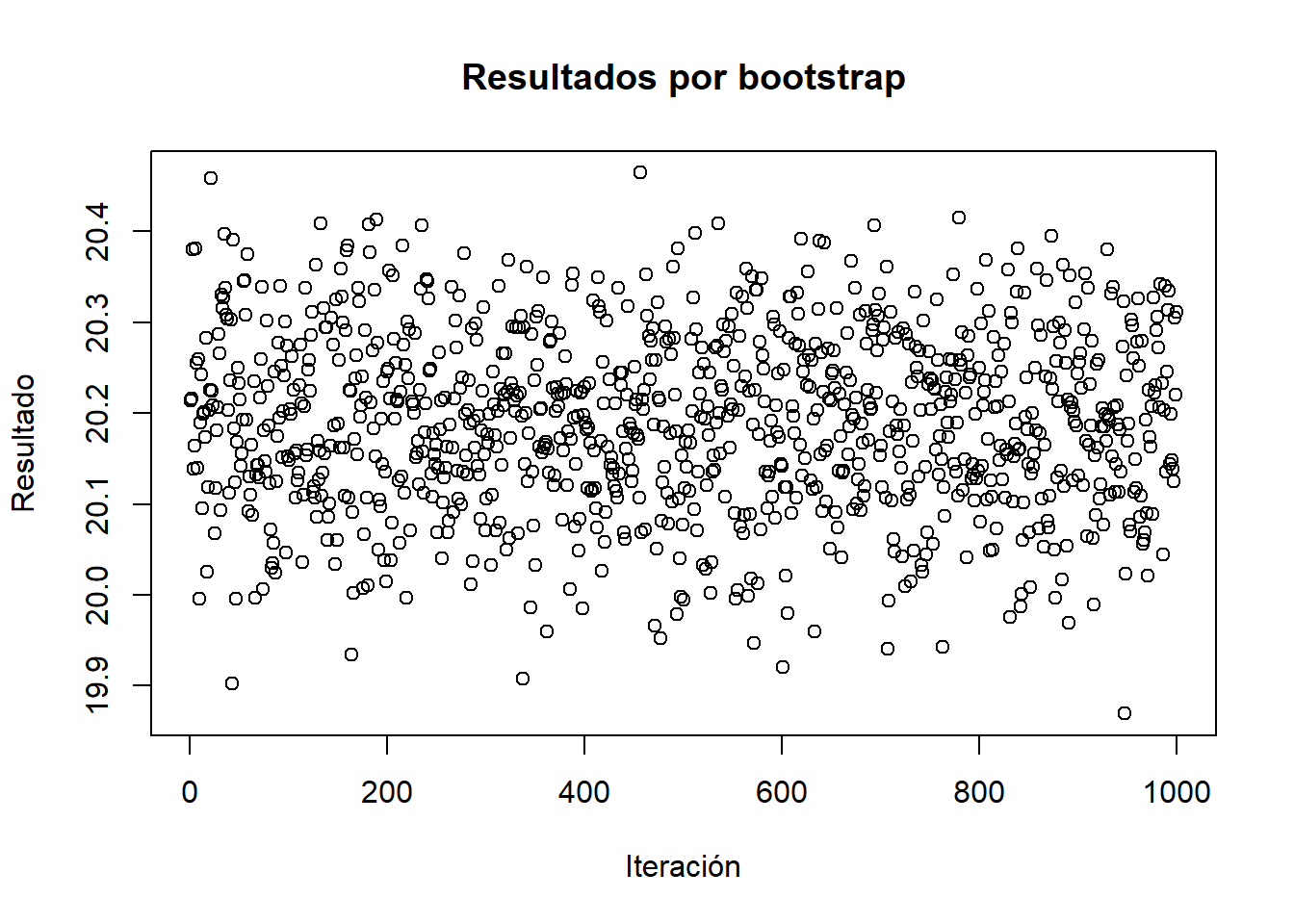
A continuación, se presenta el gráfico de las muestras bootstrap y la densidad resultante.
cat("Resultado del bootstrap: \n")
Resultado del bootstrap:
plot(results$t,main="Resultados por bootstrap",ylab="Resultado",xlab="Iteración")
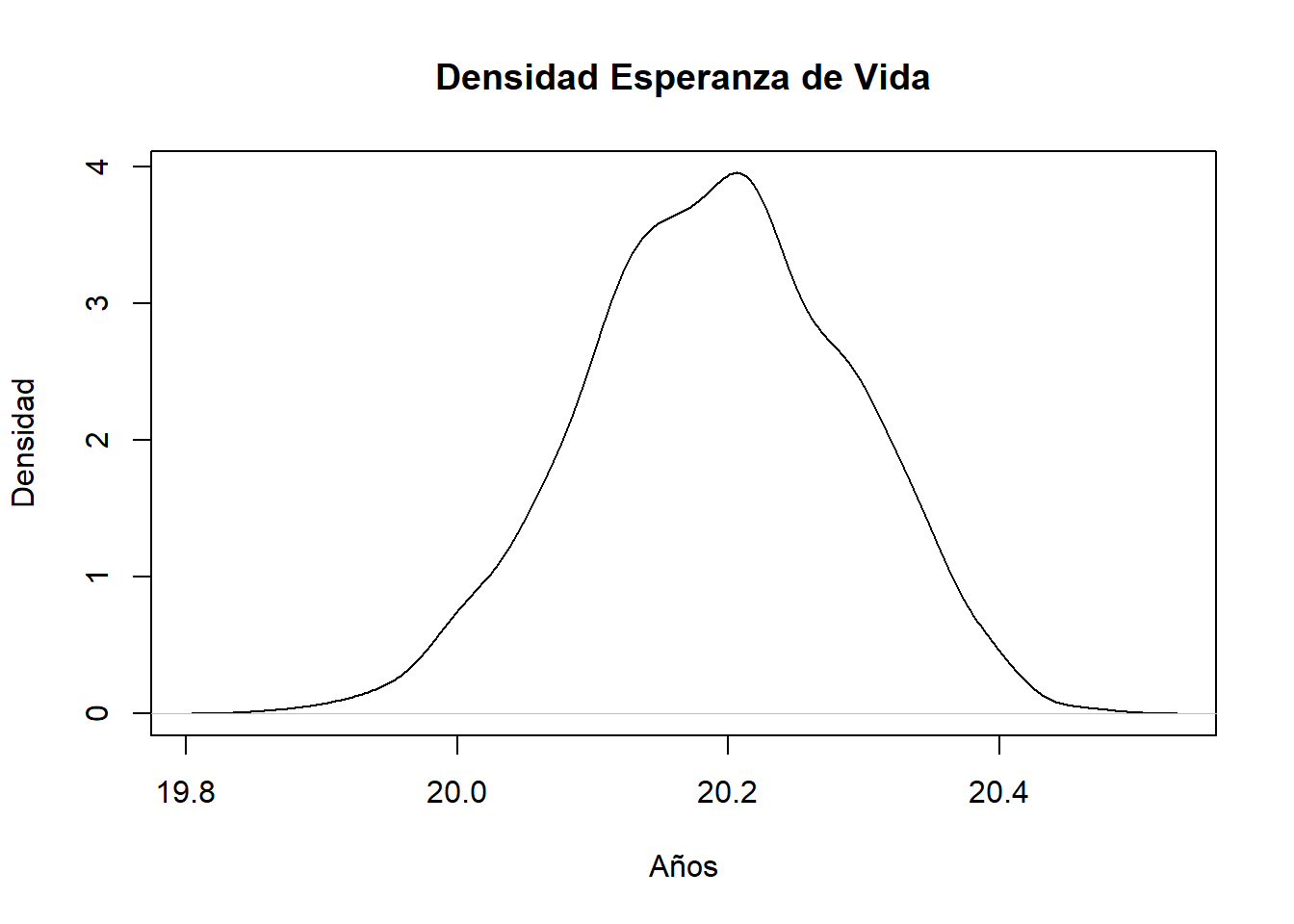
cat("densidad del bootstrap \n")
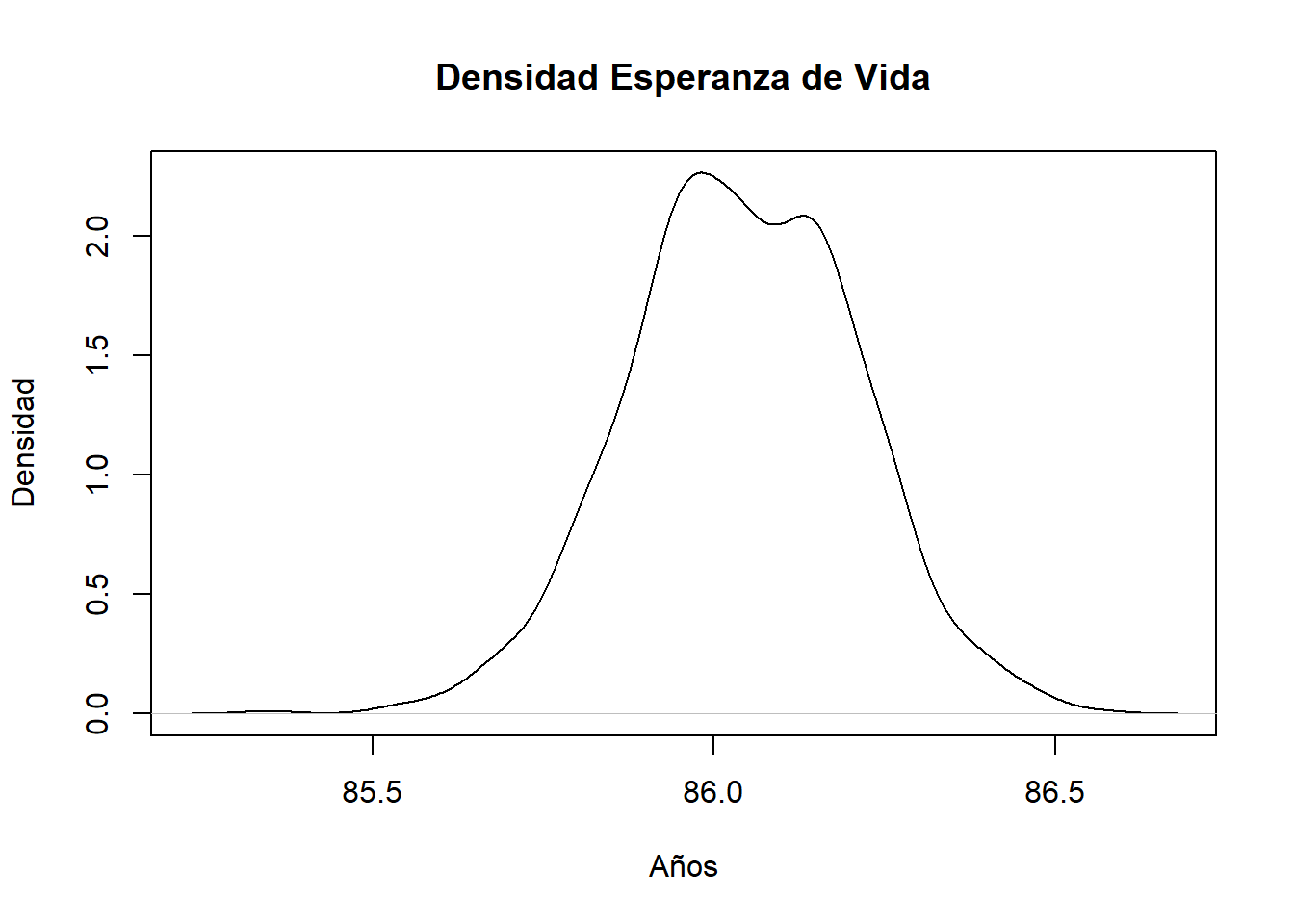
densidad del bootstrap
plot(density(results$t), main="Densidad Esperanza de Vida",xlab="Años",ylab="Densidad")
Ejemplo 5.5Esperanza de Vida residual a los 65 años
Podemos repetir el ejercicio anterior con una persona de 65 años, para esto estimaremos su esperanza de vida residual
qx65 <-read_excel("C:/Users/Usuario/Downloads/qxCero.xlsx", sheet ="Hoja2")px65=qx65px65$qx=1-qx65$qxn=length(px65$qx)cat("Esperanza de Vida residual, valor esperado: \n")
Esperanza de Vida residual, valor esperado:
(ex65<-sum(cumprod(px65$qx[2:n]))+0.5) #factor 0.5 es para estimar la esperanza continua.
plot(results$t,main="Resultados por bootstrap",ylab="Resultado",xlab="Iteración")
cat("densidad del bootstrap \n")
densidad del bootstrap
plot(density(results$t), main="Densidad Esperanza de Vida",xlab="Años",ylab="Densidad")
5.6 Introducción a la ergodicidad
Definición 5.7Promedio Ergódico o Césaro
Sea \(X_n\) una cadena de Markov que tiene por distribución estacionaria \(\pi\) y que satisface las condiciones ergódicas: irreducible, aperiódica, y recurrente Definimos el Promedio ergódico para una función \(f\) como:
\[\hat f_N=\frac{1}{N}\sum_{n=1}^N f(X_n)\]
Teorema 5.2Teorema Ergódico para MCMC Sea \(X_n\) una cadena de Markov que tiene por distribución estacionaria \(\pi\) y que satisface las condiciones ergódicas: irreducible, aperiódica, y recurrente. Entonces el promedio ergódico cumple que:
En otras palabras, la media de la cadena converge casi seguramente al valor esperado bajo la distribución estacionaria \(\pi\)
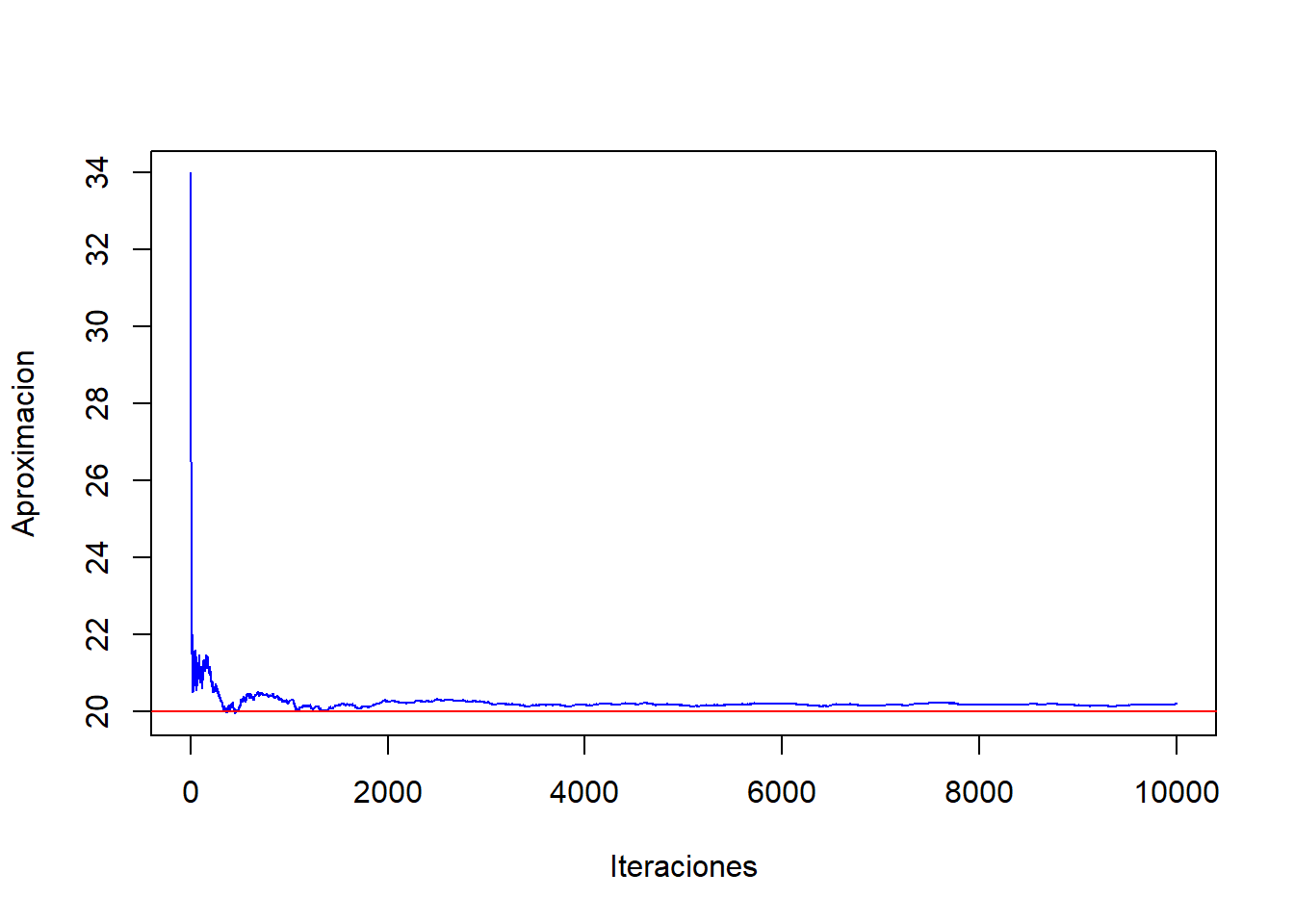
Esto sirve como prueba fundamental de convergencia: cuando observamos que \(\hat f_N\) se estabiliza cerca de la \(E_\pi[f]\), estamos viendo evidencia práctica que la cadena ha alcanzado su distribución estacionaria.
También el promedio ergódico ofrece una prueba asintótica robusta de convergencia, equivalente a la ley fuerte de los grandes número para MCMC.
Para analizar la convergencia del proceso MCMC gráficamente, por medio de los promedios ergódicos, para el caso de 65 años, podemos observar como en las primeras iteraciones el promedio es muy volátil y después inicia un estabilizarse cerca del valor esperado:
Uno de los problemas de los algoritmos de optimización, es que en ocasiones según donde se inicie la búsqueda de un mínimo puede que se encuentre un mínimo local y no el mínimo global. Si se quiere profundizar sobre este método y temas de optimización se puede revisar Goffe et al. (1994).
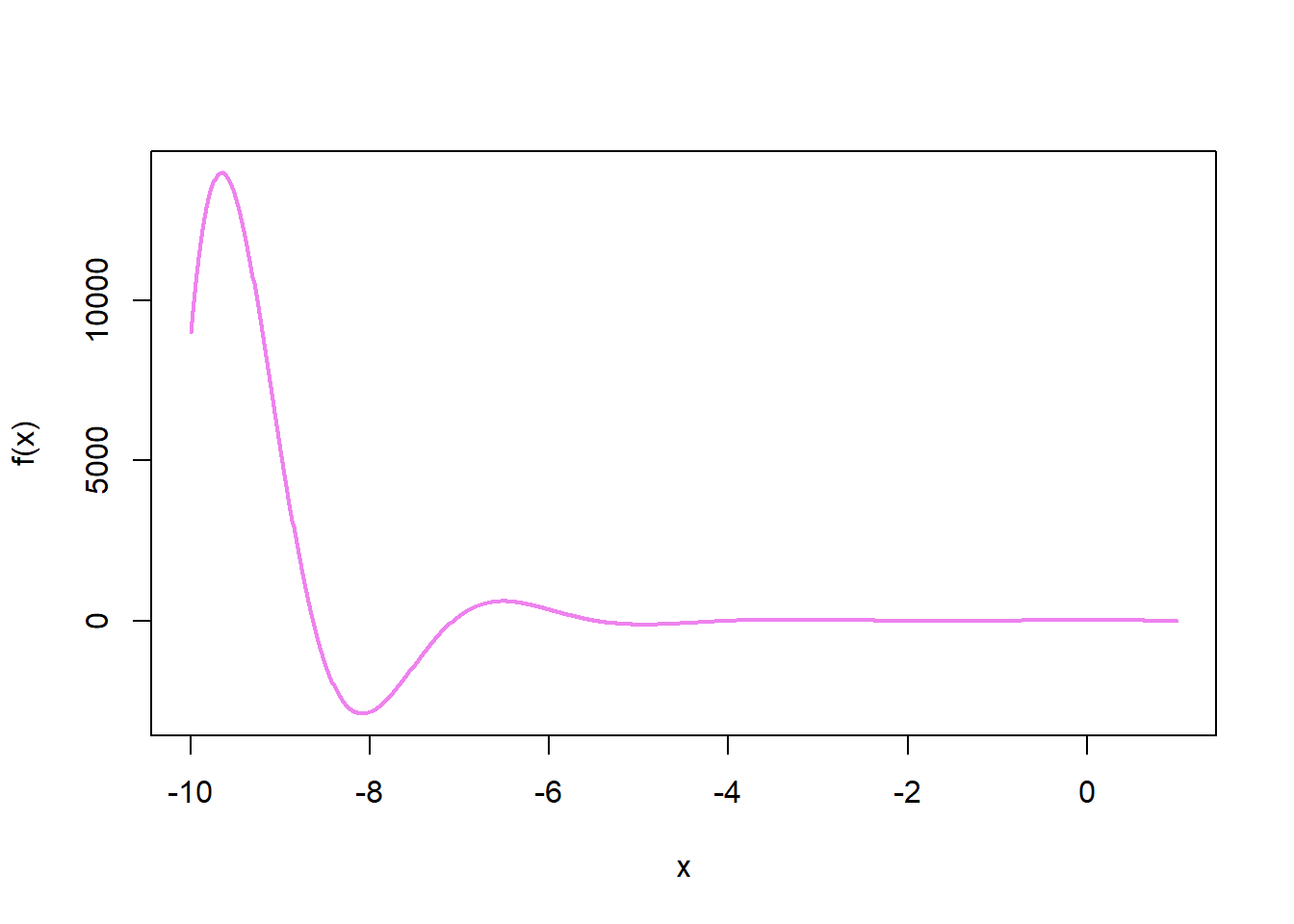
Consideremos la función:
\(f(x)=cos(2x)e^{-x}\)
Si delimitamos a \(f(x)\) en el intervalo \([-10,10]\) podemos observar que posee varios mínimos y máximos locales.
Si ejecutamos el algoritmo de Newton-Raphson para llamar el mínimo en el intervalo \([-10,10]\) obtenemos un mínimo local en \(x\approx 0.7854\)
library(numDeriv)NR <-function(f, x0, tol =1e-6, N0 =500) {# x0.....Valor inicial# N0.....Número de iteraciones# Verificar que el punto inicial no sea una raiz fx0 <-f(x0)if (fx0 ==0.0) {return(x0) } k <-1# Inicializar contador A <-NA# Inicializar vector de iteracioneswhile (k <= N0) { dx <-genD(func = f, x = x0)$D[1] # primera derivada, f'(x0) x1 <- x0 - (f(x0) / dx) # Cálculo de la aproximación siguiente A[k] <- x1 # Almacenar iteraciones# Imprimir el resultado cuando |x1 - x0| < tolif (abs(x1 - x0) < tol) { aprox <-tail(A, n=1) res <-list('Raíz aproximada'= aprox, 'iteraciones'= A, 'Número de iteraciones'= k)return(res) }# Si NR no ha alcanzado la convergencia, debe continuar x0 <- x1 k <- k +1 }print('El método falló. El número de iteraciones no es suficiente.')}NR(f,0)
Para lograr hallar el mínimo global,se necesita conocer (al menos parcialmente) la forma de la función y elegir un punto de partida relativamente cercano, también podemos usar un algoritmo llamado recalentamiento o recocido simulado (Simulated annealing o SA).
Este algoritmo toma su nombre de un proceso físico en la metalurgia, que consiste en calentar y enfriar en forma controlada un metal para cambiar ciertas propiedades física.
El algoritmo consiste en tomar un valor \(x_0\) (estado inicial) del intervalo a analizar y explorar en un vecindario alrededor de \(x_0\) un elemento \(x_1\) ( estado candidato) escogido al azar.
El algoritmo consiste en reemplazar \(x_0\) por \(x_1\) (cambiar de estado) siempre que \(f(x_1) \leq f(x_0)\) o con una probabilidad:
\(p= exp \{-\frac{f(x_1) - f(x_0)}{T} \}\)
Entre más grande es la diferencia entre \(f(x_1) - f(x_0)\) más pequeña será su probabilidad de aceptación.
El parámetro \(T\), se le conoce como temperatura, entre más pequeño sea la temperatura menor será la probabilidad de aceptación.
La temperatura \(T\) decrece con cada iteración a una tasa \(\alpha\)
\(\alpha T_{n-1} \rightarrow T_{n}\)
Cada temperatura fija genera una cadena de Markov Homogénea en un espacio de estados continuos (infinitos posibles casos). Por cada iteración de la Cadena un estado puede ser el mismo estado anterior (\(x_0\)) o uno nuevo (\(x_1\)).
El siguiente algoritmo, se implementa el SA con una distribución normal \(N(x_0,1)\), es decir para seleccionar \(x_1\) se toma de forma aleatoria con base en esa distribución, en general se puede asignar otro tipo de varianza a la distribución normal o incluso cambiar la distribución del algoritmo.
resim <-function(f, alpha=0.5, s0=0, niter,mini=-Inf,maxi=Inf) {s_n <- s0estados<-rep(0,niter)iter_count <-0for (k in1:niter) { estados[k]<-s_n T <- (1- alpha)^k #Se reduce el T según el número de iteraciones s_new <-rnorm(1, s_n, 1) #Distribución del SAif(s_new<mini){s_new=mini}if(s_new>maxi){s_new=maxi} dif <-f(s_new) -f(s_n)if (dif <0) { s_n = s_new } else { random <-runif(1,0,1)if (random <exp(-dif/T)) { s_n <- s_new } } iter_count <- iter_count +1}return(list(r=s_n,e=estados))}Resultado <-resim(f,0.1,0,1000,-10,10)cat("Punto donde se alcanza el mínimo global \n")
Punto donde se alcanza el mínimo global
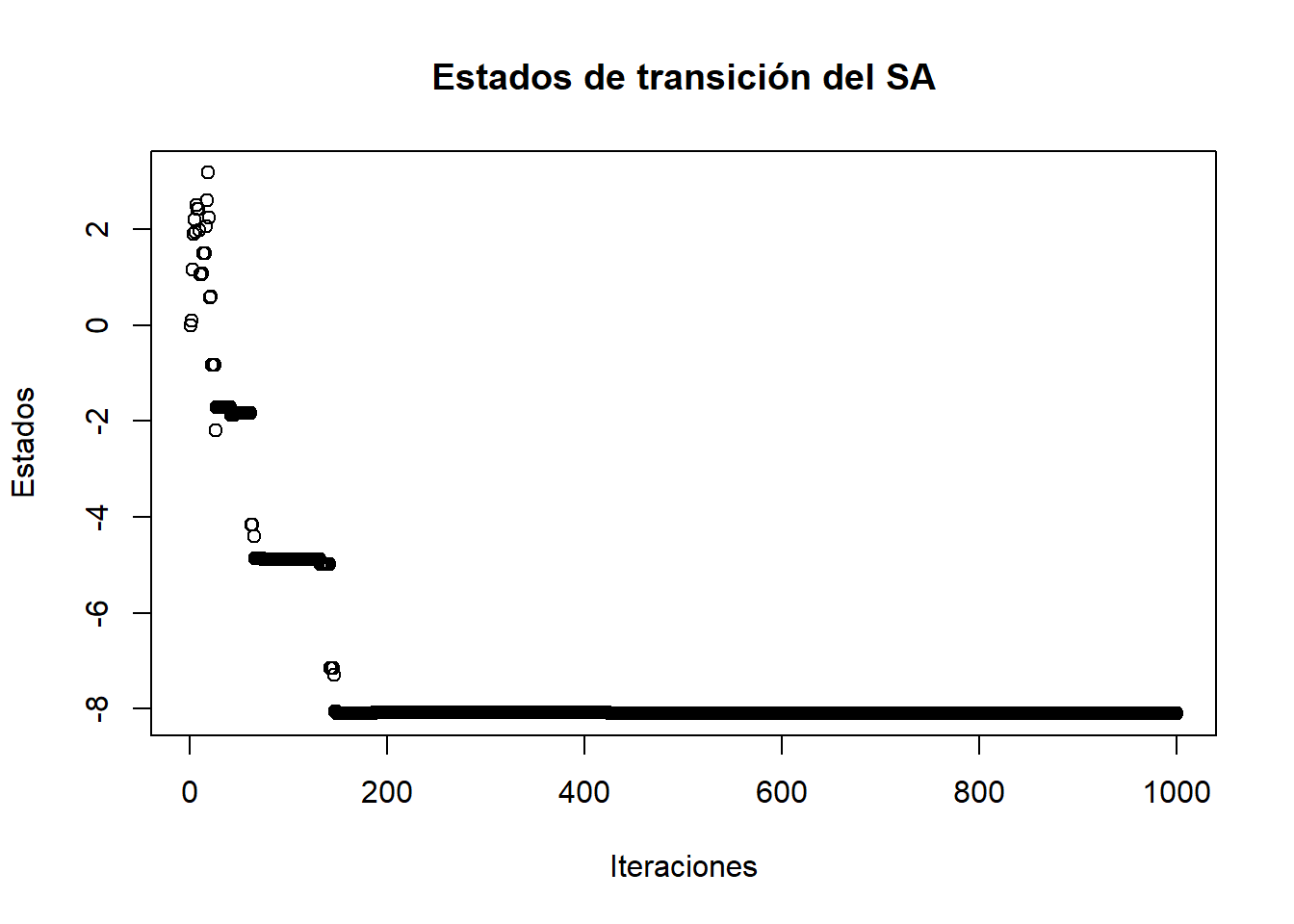
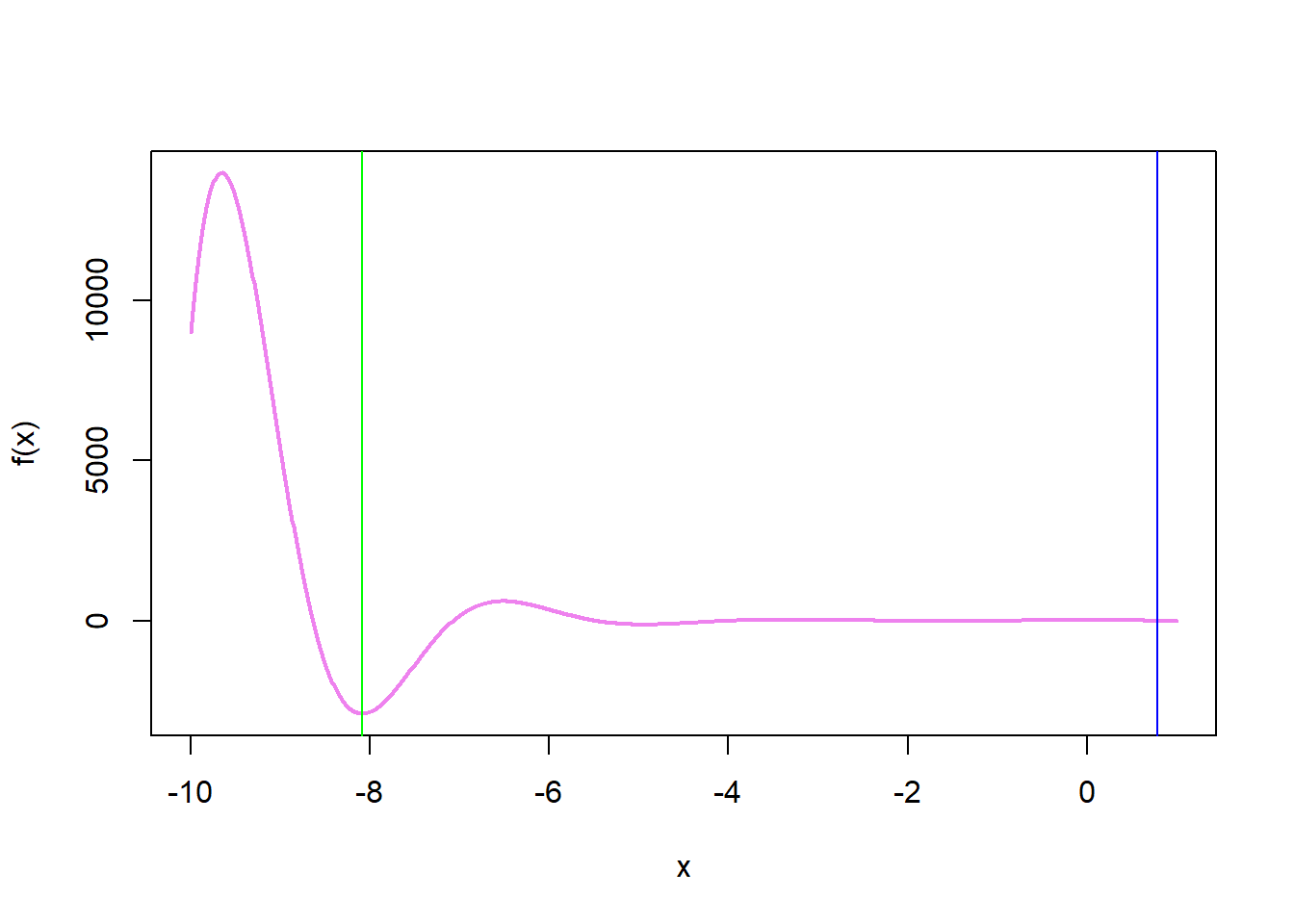
Resultado$r
[1] -8.088149
plot(Resultado$e, main="Estados de transición del SA",xlab="Iteraciones",ylab="Estados")
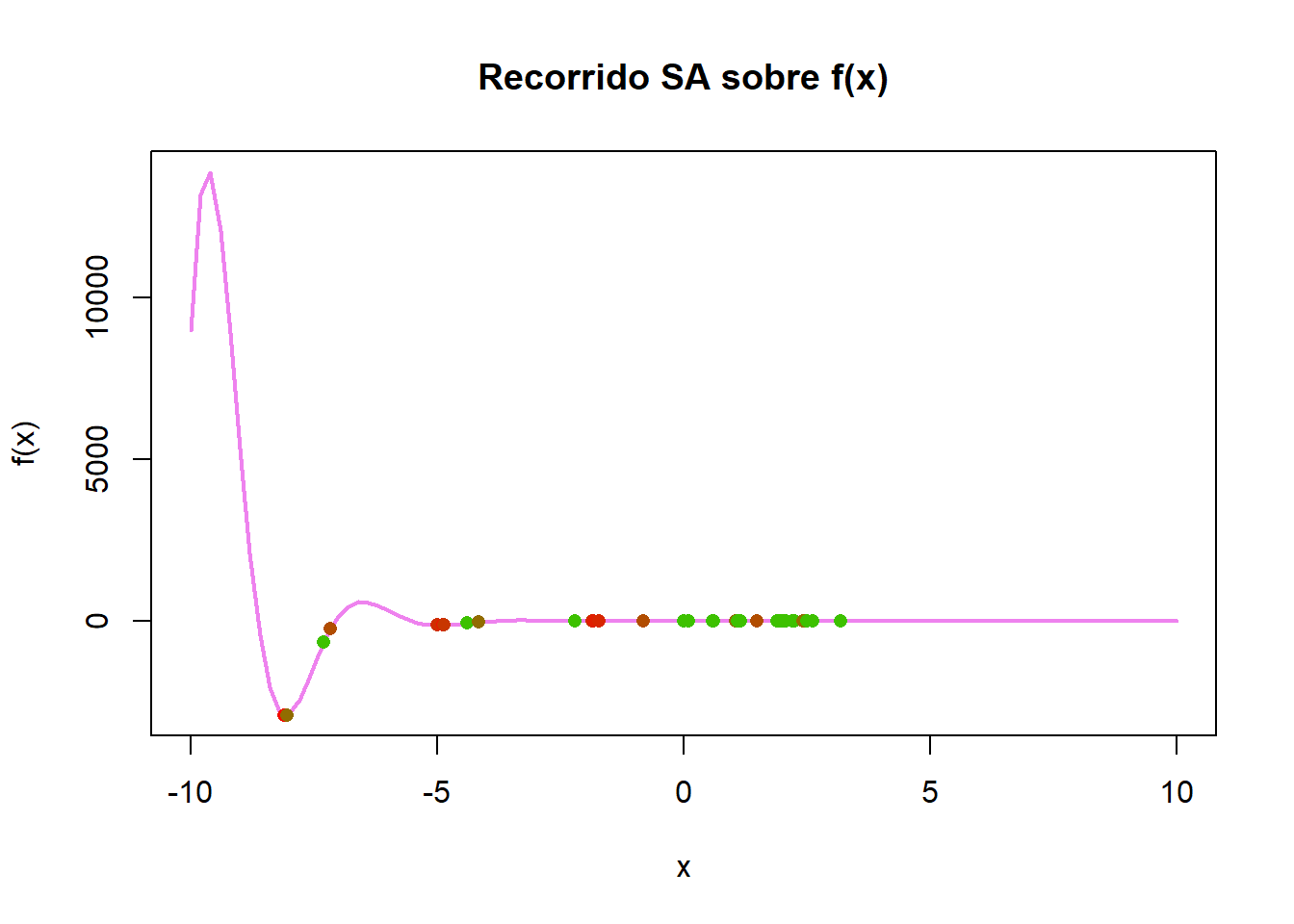
En el gráfico, podemos observar los estados donde transitó la cadena, podemos observar que con el tiempo la cadena cambia a diferentes estados, y tiende a mantenerse en algunos estados más tiempo (o más iteraciones) que en otros, para converger en un estado, que es el punto mínimo global que se busca. En el siguiente gráfico, podemos ver los estados donde permaneció más tiempo la cadena generada (color rojo)
#Estimar la veces que esta en un estadoestado_tab <-table(round(Resultado$e, 2)) estados <-as.numeric(names(estado_tab))frec <-as.numeric(estado_tab)col_pal <-colorRampPalette(c("green", "red"))(length(frec))colores <- col_pal[rank(frec)]curve(f, from=-10, to=10, col="violet", lwd=2,xlab="x", ylab="f(x)", main="Recorrido SA sobre f(x)")points(estados, f(estados), col=colores, pch=16)
Si comparamos el resultado de ambos algoritmos, recalentamiento simulado y Newton-Rhapson, partiendo del mismo punto, tenemos una diferencia notable, entre los algoritmos, claramente si usamos un punto más cercano al global, el método de Newton-Rhapson converge al mismo resultado.
Banks, J., Carson, J. S., Nelson, B. L., & Nicol, D. M. (2010). Discrete-Event System Simulation (5th ed.). Prentice Hall.
Goffe, W. L., Ferrier, G. D., & Rogers, J. (1994). Global Optimization of Statistical Functions with Simulated Annealing. Journal of Econometrics, 60(1-2), 65-99. https://doi.org/10.1016/0304-4076(94)90038-8