Las técnicas de remuestreo (resampling) es una variedad de métodos que permiten estimar la precisión de una muestra mediante el uso de subconjuntos de datos disponibles o validar modelos.
Los métodos de remuestreo son técnicas basadas en crear diferentes muestras a partir de una muestra dada y hacer una estimación de un parámetro en cada una de ellas, luego relacionando todas las estimaciones se obtiene un nuevo estimador, que con frecuencia tiene mejores propiedades que el estimador inicial.
Entre las técnicas más comunes de remuestreo esta el bootstrapping, Jackknife, validación cruzada (Cross-validation) y submuestreo.
3.2 Validación Cruzada
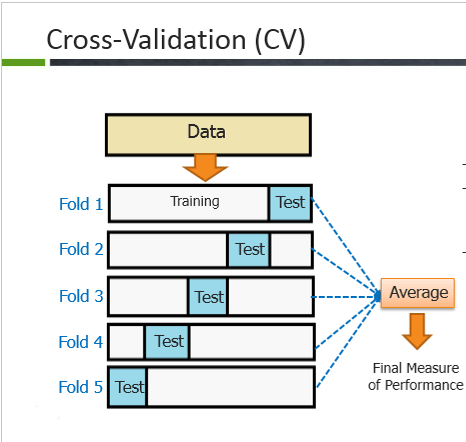
El término validación Cruzada es una clase de métodos que estiman usualmente la tasa de error de un modelo, donde se excluye una parte de las observaciones de la muestra (data de prueba o testing data) y el restante de la muestra (data de entrenamiento o training data) se usa para construir el modelo. Esto se realiza con el fin de medir la capacidad predictiva del modelo o seleccionar niveles de flexibilidad del modelo.
Definición 3.1Validación Cruzada
El remuestreo de la validación cruzada se define como:
Dada una muestra \(X=x_1,x_2,...,x_N\), se divide en \(k\) subconjuntos \(X_i\) de longitud \(l\) observaciones disjuntas, llamados folds, tal que:
\[X=\bigcup_i X_i\] Se le llama grupo de entrenamiento al subconjunto
\[X_{E,j}=\bigcup_{i \neq j} X_i\]
y la subconjunto \(X_j\) como grupo de validación o prueba.
La segmentación puede variar según el analista, pero usualmente cada grupo tienen la longitud entre el 5% al 20% del tamaño de la muestra.
Nota
En caso que \(K=1\) el método se le llama validación cruzada dejando uno fuera (Leave-One-Out, LOOCV), sin embargo este procedimiento tiene un alto costo computacional.
Sea \(Y\) el estadístico o variable a estimar y sea \(e(X,Y)\) una medida de error ( puede ser MSE por ejemplo) entre las variables explicativas \(X\) y las variables de respuesta \(Y\).
Dada una muestra \(X\) se toma una partición de \(k\) partes (folds), tenemos un estimador llamado validación cruzada \(CV_k\) definido por:
Donde se estima una fórmula para \(\hat Y\) con base en las las \(k-1\) partes distintas a \(i\), \(X_1,X_2,...X_{i-1},X_{i+1},...X_k\) llamado el conjunto de entrenamiento. Dada la fórmula para \(\hat Y\) se estiman los valores \(\hat Y_i\) según las observaciones de \(X_i\), llamado el conjunto de prueba y se estima el error \(e(X_i,Y_i)\) con las variables observadas \(Y_i\).
Observación
Entre más grande el conjunto de entrenamiento menos será el sesgo del error, pero más caro constitucionalmente la estimación del \(CV_k\).
Modelo de validación Cruzada
Ejemplo 3.1Validación Cruzada
Consideramos una serie de datos mensuales sobre la Humedad Promedio y la Precipitación promedio de una Ciudad, como se muestra a continuación:
El objetivo es crear un modelo que aproxime con una recta \(y=ax+b\), los datos entre Humedad y Precipitación, con el fin de predecir la Humedad y estimaremos \(CV_k\) del modelo, para esto usaremos como medida del error, el Error Cuadrático Medio (ECM o MSE)
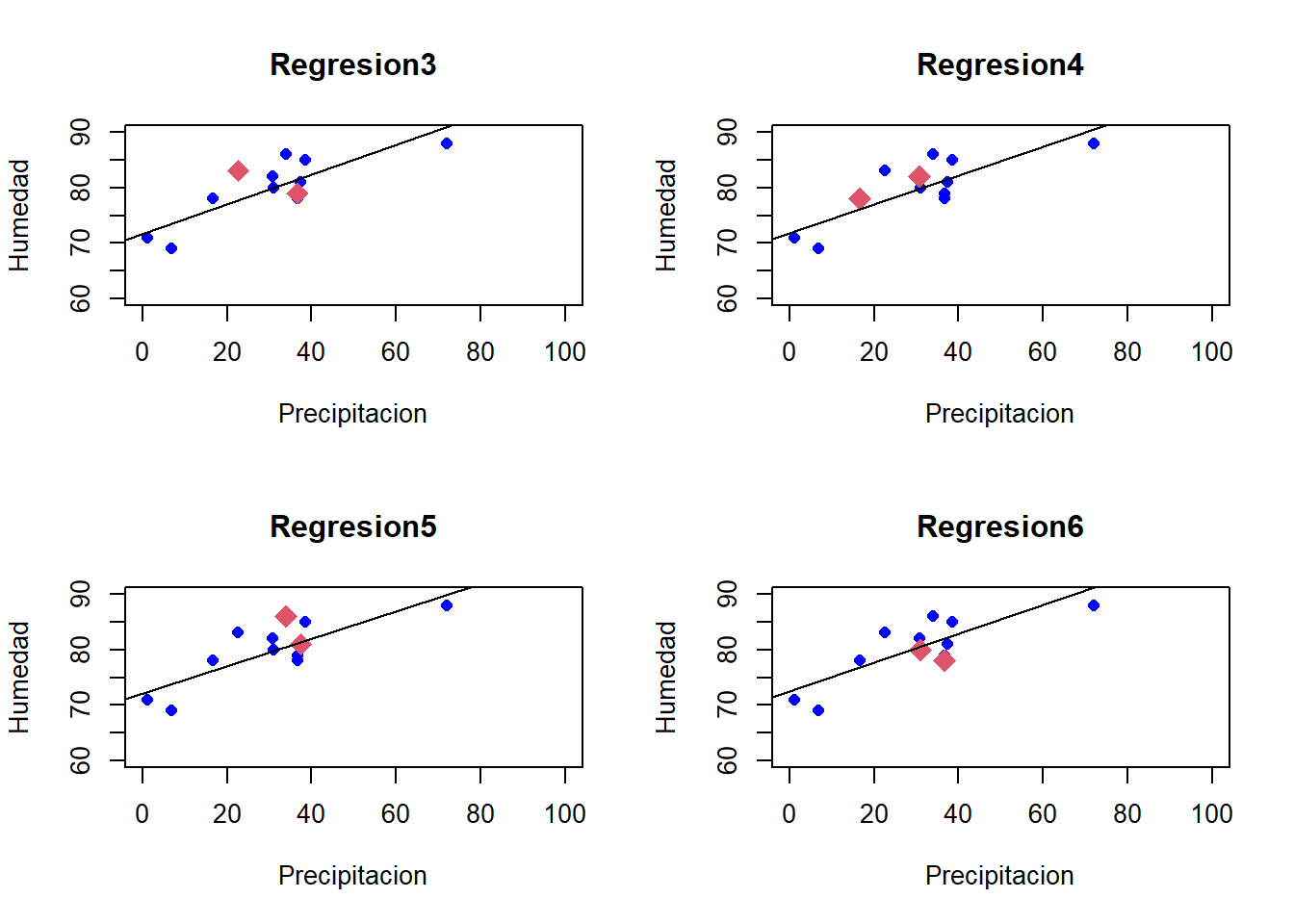
A nuestro set de datos, lo ordenaremos aleatoriamente, para crear 6 particiones, donde 10 datos de la muestra serán nuestro datos de entrenamiento y 2 nuestro datos de Prueba:
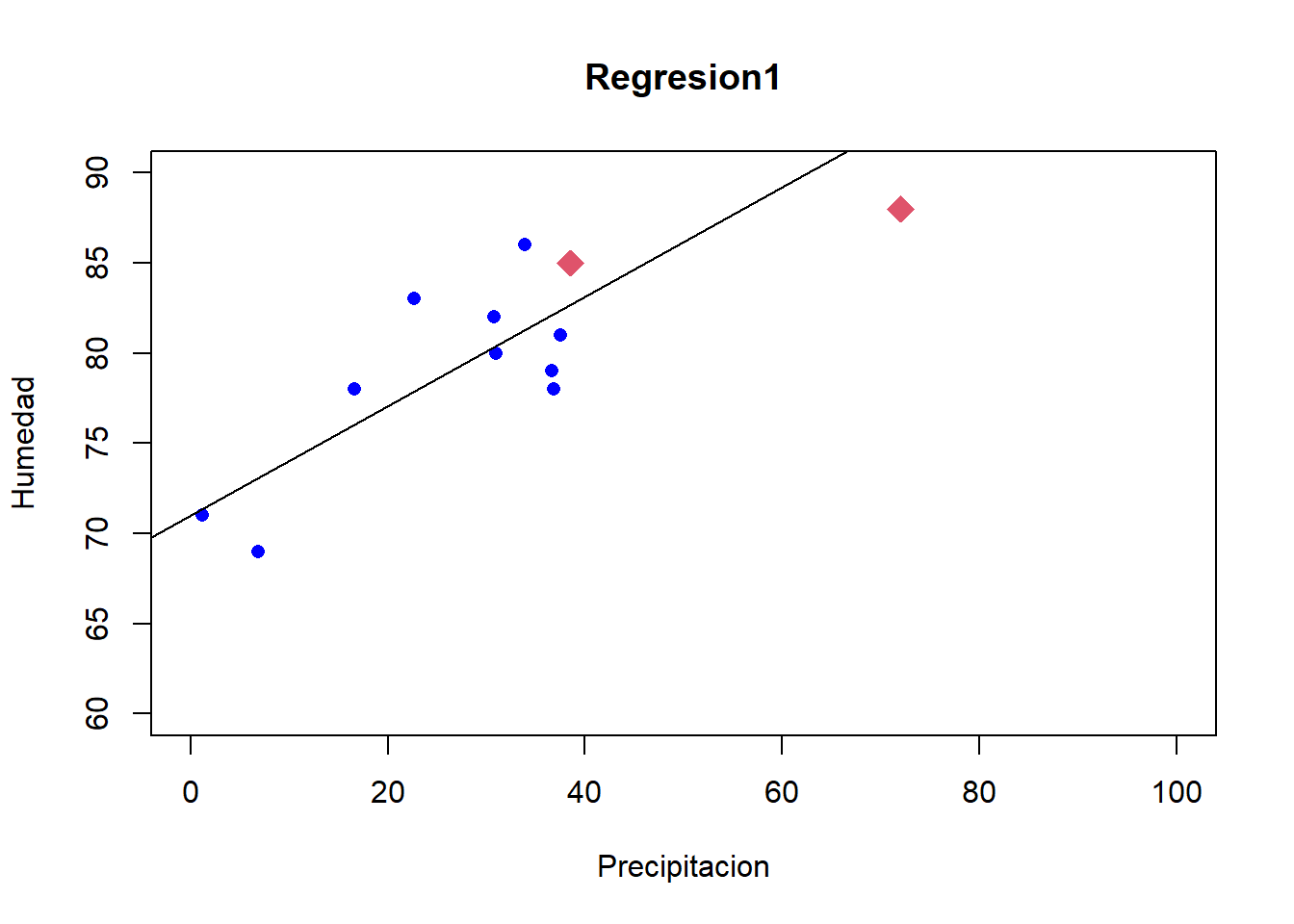
Trabajemos la primera partición, para esto tomaremos las 10 primeras observaciones como el conjunto de entrenamiento y las 2 últimas con el conjunto de Prueba
Regresion1<-lm(Humedad~Precipitacion,data=Datos.E)cat("los coeficientes de la recta son: \n")
los coeficientes de la recta son:
Regresion1$coefficients
(Intercept) Precipitacion
70.9782695 0.3041249
plot(x=Datos.E$Precipitacion,y=Datos.E$Humedad, pch =16, col ="blue",main="Regresion1",ylab="Humedad",xlab="Precipitacion", xlim=c(0,100),ylim=c(60,90)) points(x=Datos.P$Precipitacion,y=Datos.P$Humedad, pch=18,cex=2,col=2)abline(Regresion1)
Datos.estimados<-predict(Regresion1,newdata=Datos.P)cat("Los Datos estimados son: \n")
Los Datos estimados son:
Datos.estimados
11 1
82.68708 92.87526
#Error Cuadrático MedioECM1<-mean((Datos.estimados - Datos.P$Humedad)^2)cat("El Error cuadrático Medio de la primera partición es \n")
El Error cuadrático Medio de la primera partición es
ECM1
[1] 14.55889
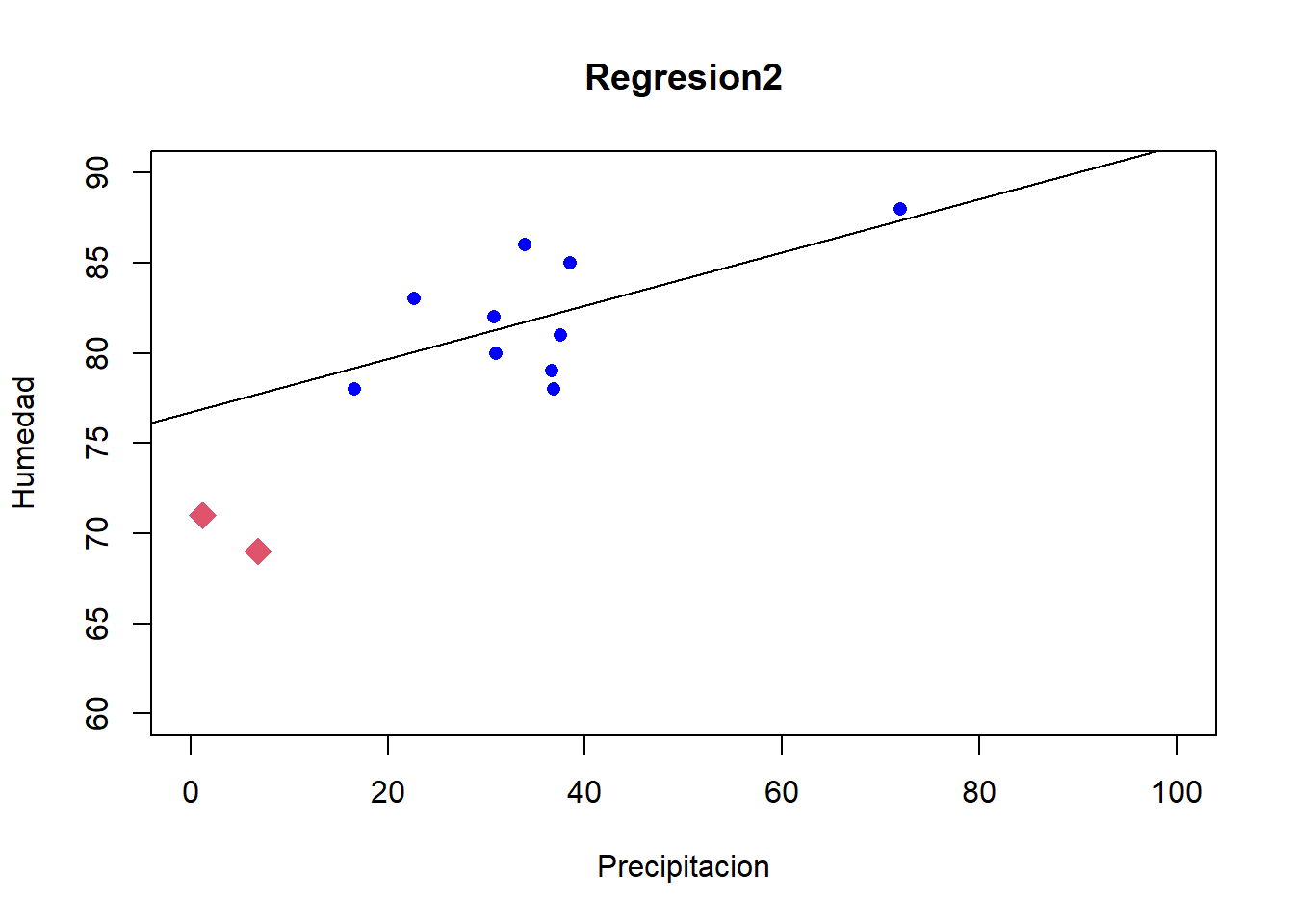
Continuaremos con la segunda partición, para esto tomaremos las 8 primeras observaciones y las 2 últimas como el conjunto de entrenamiento y las observaciones 9 y 10 como el conjunto de Prueba
Datos.E<-Datos2[c(1:8,11,12),]Datos.P<-Datos2[-c(1:8,11,12),]Regresion2<-lm(Humedad~Precipitacion,data=Datos.E)cat("los coeficientes de la recta son: \n")
los coeficientes de la recta son:
Regresion2$coefficients
(Intercept) Precipitacion
76.7319427 0.1478131
plot(x=Datos.E$Precipitacion,y=Datos.E$Humedad, pch =16, col ="blue",main="Regresion2",ylab="Humedad",xlab="Precipitacion", xlim=c(0,100),ylim=c(60,90)) points(x=Datos.P$Precipitacion,y=Datos.P$Humedad, pch=18,cex=2,col=2)abline(Regresion2)
Datos.estimados<-predict(Regresion2,newdata=Datos.P)#Error Cuadrático MedioECM2<-mean((Datos.estimados - Datos.P$Humedad)^2)cat("El Error cuadrático Medio de la segunda partición es \n")
El Error cuadrático Medio de la segunda partición es
Error_Validacion_Cruzada<-mean(ECMT)cat("El Error estimado por validación cruzada es \n")
El Error estimado por validación cruzada es
Error_Validacion_Cruzada
[1] 19.23675
3.3 Método Jackknife
El método de Jackknife fue presentado por Quenouille (1949) y Tukey (1958) generalizó la técnica y propuso su nombre actual, al ser un herramienta “aspera y lista” que puede resolver una variedad de problemas. Esta parte es tomada de Guzmán & Recuena (s.f.) , Wasserman (2006) y Fernández Casal (2023)
En las estimaciones puntuales, buscamos idealmente un estadístico, insesgado, Aunque en la práctica muchos estimadores poseen un sesgo.
En 1949, Quenouille, propuso una técnica para estimar y reducir el sesgo de un estimador (\(T_n\)) de \(\theta\), en particular cuando satisface:
\[E[T_n]=\theta+\frac{\alpha}{n}+O(1/n^2)\] El método elimina el término \(\frac{\alpha}{n}\)
Ejemplo 3.2
Sea \(S^2\) la varianza muestral para una m.a.s \(X=x_1,x_2,...,x_n\), es decir que:
\[S^2=\frac{1}{n}\sum_{n=1}^n(x_i-\bar x)^2\] Se sabe que \(S^2\) es un estimador sesgado para la varianza \(\sigma^2\), con esperanza:
\[E[S^2]=\sigma^2-\frac{\sigma^2}{n}\]
Posteriormente Tukey en 1958, generalizó el método para la varianza de \(T_n\) con el fin de estimarla y reducirla.
Definición 3.2 Sea una m.a.s \(X=x_1,x_2,...x_n\) de una variable aleatoria, la muestra i-esima de Jackknife es la muestra eliminando la i-sima observación de la muestra original.
\[{}_iX=(x_1,x_2,x_{i-1},x_{i+1},...,x_n)\]
Sea el estimador \(T_n=T_n(x_1,x_2,...x_n)\) para la variable \(\theta\). El estimador i-esimo de Jackknife se define como:
\[{}_iT_{n-1}=T_{n-1}(x_1,x_2,x_{i-1},x_{i+1},...,x_n)\] Observe que existen \(n\) estimadores de Jackknife.
Definición 3.3 El i-esimo seudo valor de Jackknife se define como:
\[{}_i \hat T_n=nT_n-(n-1){}_iT_{n-1}\] El seudo valor \({}_i \hat T_n\) es una medida de la diferencia entre el estimador y el estimador Jackknife.
La media muestral de los \({}_i \hat T_n\) es:
\[ \hat T_n=\frac{1}{n}\sum_{i=1}^n{}_i \hat T_n=nT_n-\frac{(n-1)}{n}\sum_{i=1}^n{}_iT_{n-1}\] Si \(T_n\) es un estimador sesgado de la forma:
El estimador Jackknife para la media sería \(\bar X\).
Nota
Si \(T_n\) es un estimador insesgado para \(\theta\), entonces el estimador Jackknife es el mismo estimador \(T_n\) o que el sesgo Jackknife es igual a 0. (ejercicio al lector).
Para el caso del ejemplo analizado los seudovalores \({}_i \hat T_n\) se estiman como:
donde \(\hat S^2\) es la cuasivarianza muestral ( estimador insesgado de \(\sigma^2\)).
Ejemplo 3.4Ejemplo Varianza Muestral
Sea \(\theta=\sigma^2\) la varianza poblacional. Consideremos como estimador \(T_n=S^2\) la varianza muestral, de una m.a.s. \(X=x_1,x_2,...,x_n\), sabemos:
\[b_{jack}=(n-1)\left(\frac{1}{n(n-1)}\sum_{i=1}^n\sum_{j=1,j\neq i}^{n}\left( \frac{n-2}{n-1}x_j- \frac{1}{n-1}\sum_{k=1,k\neq i, k\neq j}^{n} x_k \right)^2- \frac{1}{n}\sum_{i=1}^{n}\left( x_i- \bar{X} \right)^2\right)\] Verifiquemos que el Estimador Jackknife es un estimador insesgado. En otras palabras que:
\[E[T_{jack}]=E[T_n-b_{jack}]=\sigma^2\]
Se conoce que \(E[S^2]=\frac{n-1}{n}\sigma^2\). Estimemos \(E[b_{jack}]\)
Sea m.a.s. \(X= (10,15,20,12,8,7,18,8,10,11,14)\) de las edades de los hijos de un grupo de asegurados.
Estime la media muestral y la varianza muestral de \(X\).
Estime los remuestreos de Jackknife de la muestra (\({}_iX\))
Estime las medias muestrales y la varianza muestrales para cada muestra Jackknife (\({}_iT_{n-1}\)).
Estime \(MSE\) entre la media muestral y los \({}_iT_{n-1}\).
Nota
\(MSE=\sum (T_n-{}_iT_{n-1})^2\)
Cálcule los seudo valores de Jackknife para la media y la varianza (\({}_i \hat T_n\))
Estime el sesgo de Jacknife para la media y la varianza de la muestra.
Determine el estimador de Jacknife de la media y la varianza muestral.
Sea una muestra aleatoria simple \(X= (1,5,7,9,11,6,4,2,3,4)\).
Estime la mediana muestral de \(X\).
Estime los remuestreos de Jacknife de la muestra.
Estime las medianas muestrales para cada remuestra Jacknife.
Calcule los seudovalores de Jacknife para la mediana.
Estime el sesgo de Jacknife para la mediana.
Calcule el estimador de Jacknife de la mediana para la muestra.
Prueba que si \(T_n\) es una estimador insesgado de \(\theta\), entonces el sesgo de jackknife es cero.
3.3.1 Consistencia
Método Delta
Sea \(\{X_n\}\) una sucesión de variables aleatorias, y sea \(\{a_n\}\) una sucesión numérica, con \(g\) función real. Si
\[a_n(X_n-\mu)\to N(0,1)\] para un valor \(\mu\) y g diferenciable en \(\mu\) Entonces
\[a_n(g(X_n)-g(x))\to N(0,g'(\mu)^2)\]
Para una m.a.s. \(X=(x_1,x_2,...,x_n)\) de la v.a. \(X\) con media \(\mu\) y varianza \(\sigma^2\), por el Teorema del Límite Central se sabe que:
\[\frac{\bar X-\mu}{\sigma/\sqrt{n}} \sim N(0,1)\] Entonces si \(g\) una función real, derivable en \(\mu\), por el método Delta tenemos que:
\[\frac{g(\bar X)-g(\mu)}{\sigma/\sqrt{n}} \sim N(0,g'(\mu))\] Si \(T_n=g(\bar X)\) tenemos que:
\[\frac{T_n-g(\mu)}{\sigma_n} \sim N(0,1)\]
con \(\sigma_n^2=\sigma^2g'(\mu)^2/n\), la varianza asintótica de \(T_n\)
Teorema 3.1Consistencia de Jackknife
Sea \(X\) una v.a., y sea \((x_1,x_2,...,x_n)\) una m.a.s de \(X\) y \(T_n=g(\bar X)\) con \(g\) continua en \(\mu\). Supongamos que \(\sigma^2\) existe y que \(g'(\mu) \neq 0\). Entonces, el estimador jackknife de la varianza de \(T_n\) es fuertemente consistente, es decir que
donde \(\sigma_n^2=\sigma^2g'(\mu)^2/n\), la varianza asintótica de \(T_n\)
3.4 Remuestreo Bootstrap
Sea \(X\) una v.a. con distribución desconocida \(F\), y sea \(X=(x_1,...,x_n)\) una m.a.s. de X, y \(T_n=T_n(x_1,...,x_n)\) un estadístico. El objetivo es calcular ciertas características del estadístico \(T_n\) como su varianza, el error de estimación, o su distribución, con lo que se podría construir intervalos de confianza. Esta sección se basa en Wasserman (2006) y Fernández Casal (2023).
En el caso, por ejemplo, de la varianza de un estadístico, \(T_n\), tenemos que esta se obtiene de la forma
Claramente, si \(F\) es desconocida, la expresión anterior no se puede evaluar. El método bootstrap plantea como solución, aproximar la expresión anterior sustituyendo la distribución desconocida por una estimación de \(F\). Podemos tener dos metodologías bootstrap:
Bootstrap no paramétrico Se origina que no conocemos la distribución que sigue nuestra m.a.s, y estimamos \(F\) usando la distribución empírica \(\hat F_n(x)\).
Bootstrap paramétrico En este caso, conocemos la distribución \(F\) de la m.a.s., pero no conocemos los parámetros \(\theta=(\theta_1,...,\theta_k)\) de la distribución \(F\), esta metodología busca la estimación de \(\hat \theta\).
Para esta sección desarrollaremos el Bootstrap no paramétrico.
Para un estadístico \(T_n\), si tenemos varias muestras de la población, se puede estimar
\[P(T_n \leq x)\]
Pero en ocasiones lo que contamos es con una sola muestra grande de tamaño \(n\). Si la muestra es suficientemente grande debería ser una buena representación de la población, lo que nos permite realizar muestras replicadas con reemplazo de la muestra original, y utilizarla como muestras aleatoriamente simples.
La cantidad de muestras con reemplazo son \(n^n\)
Esta es la idea del método Bootstrap, propuesto por Efron (1979) , permite como se indicó encontrar propiedades de los estadísticos como una generalización del método de Jackknife y utiliza el método de Monte Carlo para hallar \(F\) y estimar sus características.
Definición 3.4Definición Muestra Bootstrap
Sea \(X=(x_1,...,x_n)\) una m.a.s. de X, y \(T_n=T_n(x_1,...,x_n)\) un estadístico, el vector \(X^{*}_{b}=(x_1^{{*}},x_2^{{*}},...,x_n^{{*}})\)se denomina una muestra bootstrap, es decir una muestra con reemplazo de la m.a.s y el estimador i-esimo bootstrap \(T_n^{{*}}\)se define como \(T_i^{{*}}=T_n(x_1^{{*}},x_2^{{*}},...,x_n^{{*}})\) con \(i=1,...n^n\).
Si la probabilidad de asignar un determinado valor en la entrada i-esima es del mismo peso, se indica que es un Bootstrap uniforme o Naïve, es decir:
Observe en el ejemplo Ejemplo 3.6 que en la muestra bootstrap puede no sólo permutar los lugares las variables de la muestra, si no también repetir valores.
Para una muestra de \(n\) elementos existen \(n^n\) muestras bootstraps.
Escogencia de las muestras bootstraps
En ocasiones no es viable tomar las \(n^n\) muestras bootstraps, si no un conjunto de \(B\) muestras, sobre todo por el costo computacional del método. Algo importante es que la cantidad de muestras \(B\) no afectan la consistencia del modelo, pero si influyen en la precisión numérica de las aproximación de los resultados. Aunque no existe una regla establecida, se suele usar los siguiente parámetros:
Cantidad de muestras B
Uso recomendado
B = 50 – 200
Para estimaciones rápidas exploratorias
B = 500 – 1000
Estimaciones razonablemente estables
B = 5000 o más
Para estimar cuantiles, intervalos con alta precisión (percentiles)
B = 10000 o más
Solo si el costo computacional es bajo o se necesita gran precisión
También esta el mínimo de Hall ( Hall (1992) ) , que es una regla empírica que dice que:
\[
B \geq \frac{100}{\alpha}
\]
donde \(\alpha\) es el nivel de significancia para los intervalos de confianza.
Por ejemplo para un Intervalo de Confianza del 95%, es decir con un \(\alpha =0,05\) , entonces:
\[
B\geq 2000
\]
3.4.1 Distribución Bootstrap
Para encontrar una distribución del estimador \(T_n\), tenemos que:
\[P(T_n \leq x)=\int I_{(T_n(X) \leq x)}dF\]
Usando las muestras Bootstrap tenemos la aproximación
Podemos aproximar \(E[g(T_n(x))]\) por medio de las muestras bootstrap
\[E[g(T_n(x))]=\frac{1}{n^n}\sum_{i=1}^{n^n} g(T_i^{{*}})\] Dado el costo computacional del muestreo Bootstrap acotamos la aproximación en \(B\) muestras:
Observe que este estimador es “ideal” ya que para un \(n\) muy grande, es prácticamente imposible calcularlo, por lo que se acota para hacerlo computacionalmente operativo a una cantidad de \(B\) muestras.
3.4.3 MSE Bootstrap
También podemos establecer un error cuadrático medio, del proceso bootstrap definido como:
Consideremos una distribución empírica \(\hat F=F_n\) como aproximación de \(F\). Para la aproximación bootstrap, tomaremos B muestras bootstrap uniforme \(X^{*}_{b}=(x_{1,b}^{{*}},x_{2,b}^{{*}},...,x_{n,b}^{{*}})\) con \(b=1,2,..., B\)
\[E[\bar X_b^{*}]=\frac{1}{n}\sum_{i=1}^nE[x_i^{*}]=E[x^{*}]\]\[E[x^{*}]=\sum_{j=1}^nx_jP(x=x_j), \; \text{por ser uniforme}\]\[E[x^{*}]=\sum_{j=1}^n\frac{1}{n}x_j=\bar X\]\[\Rightarrow E[\bar X_b^{*}]= \bar X\] Por otro lado:
Observe que la esperanza de \(R\) y \(R^{{*}}\) coinciden pero sus varianzas no son iguales, aunque asintóticamente la varianza de \(R^{{*}}\) es igual a la varianza de R
\[var[R^{{*}}]=\frac{S^2}{\sigma^2} \to 1=var[R] \; \text{ cuando } n\to \infty\]
Podemos hacer un cambio en las variables de la muestra tal que \((\tilde x_1,...\tilde x_n)\) donde: \(\tilde x_i=\bar X+\frac{\sigma}{S_n}(x_i-\bar X)\), para \(i=1,...,n\), como ejercicio comprobar que con la nueva muestra:
\[E[R]=E[R^{{*}}]\]\[Var[R]=Var[R^{{*}}]\]
En general tenemos tres métodos para estimar un intervalo de confianza.
Método 1: Intervalo Normal
Este método simple que se basa en el intervalo de confianza normal, sin embargo este no es preciso si nuestro estimador \(T_n\) no es normal.
\[T_n \pm Z_{1-\alpha/2}\sigma_{boot} \tag{3.2}\]
Método 2: Intervalos Pivotales
Se basa como el ejemplo desarrollado anteriormente en una función pivotal, si \(\theta=F(\theta)\) y como estimador \(\hat \theta_n=T(\hat F_n)\). Definimos la función pivotal como \(R_n=\hat \theta_n-\theta\), sea \(\hat \theta_{n,1}^{*}\),…,\(\hat \theta_{n,B}^{*}\), los estimadores obtenidos con \(B\) muestras bootstrap (replicaciones) de \(\hat \theta_n\).
Sea \(H(r)\) la distribución del pivot:
\[H(r)=P(R_n\leq r)\] Definimos los puntos \(a\) y \(b\) como:
Si conociéramos la distribución \(H\) los valores \(a\) y \(b\),serían exactos, desafortunadamente desconocemos \(H\) por lo que debemos realizar un estimación bootstrap de \(H\):
donde \(R^{*}_{n,b}=\hat \theta_{n,b}^{*}-\hat \theta_n\)
De las muestras \(R^{*}_{n,1}, ..., R^{*}_{n,B}\) el \(\beta\) cuantil lo denotaremos como \(r_\beta^{*}\). Podemos aproximar los valores de \(a\) y \(b\) como:
\[\hat a = \hat \theta_n -\hat H^{-1}(1-\alpha/2)=\hat \theta_n-r_{1-\alpha/2}^{*}=2\hat \theta_n- \theta_{n,1-\alpha/2}^{*}\]
\[\hat b = \hat \theta_n -\hat H^{-1}(\alpha/2)=\hat \theta_n-r_{\alpha/2}^{*}=2\hat \theta_n-\theta_{n,\alpha/2}^{*}\]
Donde \(\theta_{n,\beta}^{*}\) es el percentil \(\beta\) de la muestra \(\hat \theta_{n,1}^{*},...,\hat \theta_{n,B}^{*}\)
El intervalo Pivotal bootstrap de nivel de confianza \(1-\alpha\) para el estimador \(\hat \theta_n\) es:
\[IC_{boot}= \left(2\hat \theta_n-\theta_{n,1-\alpha/2}^{*}, 2\hat \theta_n- \theta_{n,\alpha/2}^{*}\right) \tag{3.3}\] cuando \(n \to \infty\) entonces \(P(IC_{boot})\to 1-\alpha\)
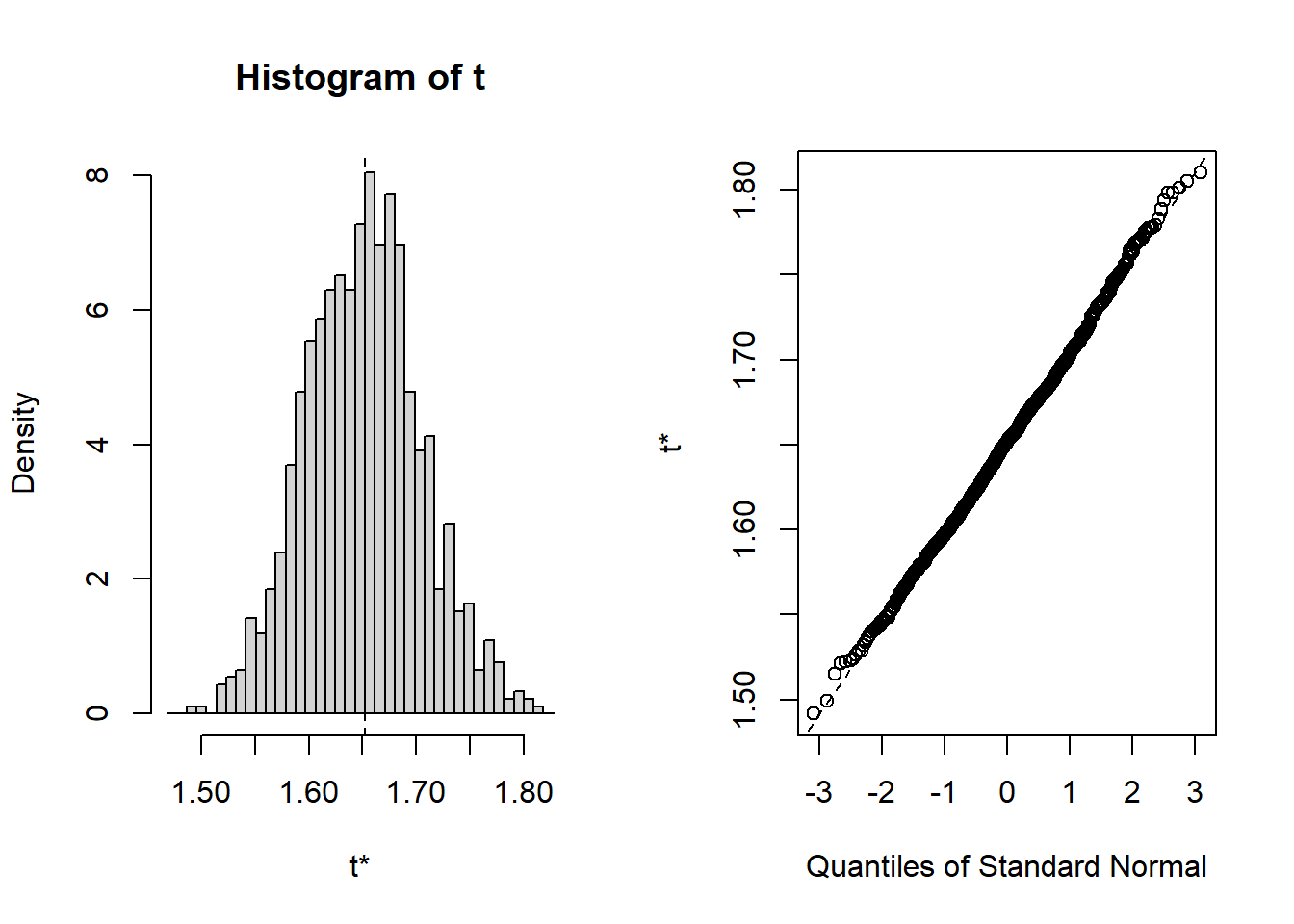
Nos interesa encontrar un estimador para \(exp(\mu)\) de una m.a.s con media \(\mu=0.5\) y \(\sigma^2=1\), de una distribución lognormal, el valor real es \(\sqrt{e} \approx 1.64872\).
construiremos una muestra de 1000 observaciones
set.seed(2025)m<-rlnorm(1000,0.5,1)
Un estimador para \(exp(\mu)\) es \(\hat{\theta}_1 = \exp\left( \frac{1}{n} \sum_{i=1}^n \log X_i \right)\). Este es el estimador de máxima verosimilitud e insesgado.
Para nuestra muestra \(\hat{\theta}_1\) sería
(theta_1 <- (exp(mean(log(m)))))
[1] 1.652322
Si trabajamos con \(Y_i=\ln(X_i)\), el log-espacio de la nuestra, podemos generar otro estimador \(\hat{\theta}_2\), dado que sabemos que:
\(Y_i \sim N(\mu, \sigma^2)\)
Usando la función generadora de momentos \(M_Y(t)=E[e^{tY}]\), tenemos que:
Sea \(X=(x_1,...,x_n)\) una muestra m.a.s sin datos repetidos (todos distintos), muestre que si no importa el orden de los elementos existen
\[\binom{2n-1}{n}\] muestras bootstrap.
Indique si esta de acuerdo o no con las siguientes afirmaciones:
La distribución bootstrap de un estadístico coincide con la distribución muestral de ese estadístico.
La técnica bootstrap sólo puede aplicarse cuando trabajamos con variables cuantitativas.
Respuesta Ambas son falsas, la distribución bootstrap es una apróximación a la distribución muestral, pero no es exacta (su esperanza es la distribución muestral), por ejemplo los intervalos de confianza no son centrados con respecto a estimador. Para la segunda afirmación, la técnica consiste en tomar muestras con reemplazos de una muestra inicial, para obtener la distibución bootstrap de un estadístico. Esta técnica puede utilizarse cuando la variable es cuantitativa o cualitativa, por ejemplo podemos usarla para estimar el porcentaje de individuos de una población de determinada categoría.
-Realizar los ejercicios dejados al lector.
-Realizar ejercicios del Capitulo 8 del libro Wasserman (2006) .
3.5 Submuestreo
Las técnicas de submuestreo (downsampling) son una técnica de remuestreo utilizada para reducir el tamaño de una muestra o conjunto de datos, eliminando alguna observaciones, las razones de utilizar submuestreo son dos:
Costo computacional de un modelo, reducir el tamaño de la muestra para ejecutar el modelo con menos datos.
Para casos de clasificación supervisada con clases desbalanceadas, estos son casos donde un alto porcentaje de la muestra pertenece a la clase \(A\) y la otra clase \(B\) tiene pocos elementos.
Ejemplo 3.8Cartera de Crédito
Un ejemplo, de una clasificación supervisada con clases desbalanceadas, es una cartera de crédito, donde se quiere estimar la probabilidad de impago de los clientes, usualmente en estos casos la categoría de prestamos al día posee la mayoría de créditos.
En casos de clasificación supervisada con clases desbalanceadas, lo usual es aplicar una técnica de submuestreo para la clase con mayor datos o aplicar una técnica de SMOTE (Synthetic Minority Over-sampling Technique) a la clase con menos datos, o una mezcla de ambas técnicas.
Las técnicas de submuestreo se formalizan en el libro Subsampling ( Politis et al. (1999) ) donde los autores realizan una propuesta alternativa al bootstrap por medio de submuestreo. Aunque podemos usar de referencia históricas los trabajos de Nyquist (1928) y Shannon (1949) como trabajos previos para las técnicas de submuestreo, así como el método Jackknife se podría clasificar como una técnica de submuestreo.
Sea \(X\) una v.a. con distribución desconocida \(F\), y sea \(X=(x_1,...,x_n)\) una m.a.s. de X, y \(T=T(F)\) un estadístico, como la media, la varianza, mediana, entre otros.
Sea \(\hat{T_n}=T(\hat F_n)\) , donde \(\hat F_n\) es la distribución empírica con los datos de la muestra de \(X_n\). Lo que queremos realizar es encontrar la distribución entre \(\hat T_n\) y el valor real de \(T\) por medio de:
\[
\sqrt{n}(\hat T_n-T)
\]
Que representa la variabilidad del estimador respecto al valor real del parámetro, esto nos ayuda a construir intervalos de confianza o estimaciones del error.
Nota:
Recordemos que por el Teorema de Limite Central para Estimadores (TLCE), ver Método Delta, tenemos que asintóticamente, que para el estimador \(\hat \theta\) de \(\theta\) , se tiene:
En este caso, al desconocer \(F\), tampoco conocemos el comportamiento de la varianza \(\sigma^2\).
Definición 3.5Definición Submuestra
Sea \(X=(x_1,...,x_n)\) una m.a.s. de X, y \(\hat T_n=T_n(x_1,...,x_n)\) un estadístico, el vector \({}_iX_{b}=(x_1^{(i)},x_2^{(i)},...,x_b^{(i)})\) con \(b<n\), se denomina una submuestra, esta submuestra es sin reemplazo de la m.a.s y el subestimador i-esimo de la submuestra \({}_i\hat T_n\)se define como \({}_i\hat T_b=T_b(x_1^{(i)},x_2^{(i)},...,x_b^{(i)})\) con \(i=1,...N_b\). donde \(N_b=\binom{n}{b}\) o una muestra aleatoria de \(\binom{n}{b}\) si \(N_b\) es muy grande.
Observe que si \(b=n-1\) estaríamos en el caso de las muestras jackknife.
Escogencia de las submuestras
A diferencia del modelo Bootstrap donde seleccionamos una cantidad de \(B\) muestras, y la escogencia de esa cantidad no afectaba la consistencia del modelo, solamente la precisión del mismo. En caso de las submuestras, la elección del tamaño de \(b\) es muy importante ya que que puede afectar la consistencia del modelo.
Si \(b\) es relativamente pequeño, se puede perder entre las submuestra información, agregar mucha volatilidad a los resultados y si \(b\) es muy grande se puede perder la independencia entre los subestimadores y podría aumentar el error o riesgo.
Según Politis et al. (1999) el \(b\) debe cumplir con:
La primera condición \(b \rightarrow \infty\) pretende que cada submuestra tenga suficiente información y que sea razonablemente consistente, mientras que la segunda condición \(\frac{b}{n}\rightarrow 0\) pretende disminuir el sesgo introducido por trabajar con submuestras más pequeñas que la muestra original, de esta forma garantizar el comportamiento asintótico. Ambas condiciones hace que podamos aplicar el TLCE, nos permite estimar la varianza del estimador en forma correcta.
Aunque no existe una fórmula exacta, existes reglas heurísticas, las cuales se basan es un \(b=n^\gamma\) con \(\gamma \in [0,1]\). Para muestras grandes \(n \geq 500\) se recomienda escoger un \(b\) entre \(n^{0.5}\) y \(n^{0.9}\), un valor práctico es \(b=\left\lfloor n^{0.7} \right\rfloor\) , por ejemplo si n=1000, entonces \(b\in[32,501 ]\), y un número práctico del tamaño de las submuestras sería 125.
La sección del \(b\) puede hacerse empíricamente, aunque una forma más adecuada es minimizando el error cuadrático medios (MSE) mediante validación cruzada.
3.5.1 Distribución Submuestreo
Definición 3.6Disbribución Submuestreo Se define la distribución empírica del submuestreo como:
Obtenido la distribución \(L_{n,b}(x)\) , podemos construir un intervalo de confianza \(1-\alpha\) para \(T\) determinando los cuantiles \(\tau_{\alpha/2}\) y \(\tau_{1-\alpha/2}\) de \(L_{n,b}(x)\) , de tal manera que el intervalo sería:
ejercicio al lector que es el intervalo de confianza.
Ejemplo 3.9Ejemplo Submuestreo
Estimaremos el ejemplo Ejemplo 3.7 que realizamos anteriormente de un estimador para \(exp(\mu)\) de una m.a.s con media \(\mu\), de una distribución lognormal, el valor real es 1.64872.
set.seed(2025)m<-rlnorm(1000,0.5,1)n<-length(m)#Valores del submuestreob <-floor(n^0.7) #tamaño de la submuestraNb<-1000#número de submuestreo a considerartn<-numeric(Nb) #crea el vector de submuestrasfor (i in1:Nb) { indices <-sample(1:n, size = b, replace =FALSE) x_b <- m[indices] tn[i] <-exp(mean(log(x_b)))}tn_estimado<-mean(tn) #estimador de la submuestrasesgo<-tn_estimado-(exp(1/2))#Otros valoresvarianza<-var(tn)desv<-sd(tn)cat("Estimador Submuestreo:", tn_estimado, "\n")
Estimador Submuestreo: 1.656942
cat("Sesgo estimado:", sesgo, "\n")
Sesgo estimado: 0.008220641
cat("Varianza estimada:", varianza, "\n")
Varianza estimada: 0.01806368
cat("Desviación estándar:", desv, "\n")
Desviación estándar: 0.1344012
3.5.2 SMOTE
A inicios de esta sección se mencionó que para casos de clasificación supervisada con clases desbalanceadas, la clase con menos datos se puede usar el método SMOTE (Synthetic Minority Over-sampling Technique). Esta técnica se basa en crear sintéticamente nuevas observaciones con base en una combinación lineal entre puntos cercanos (vecinos más cercanos), esta forma de crear observaciones evita sobreajustes que ocurren cuando se duplican las observaciones y preserva la estructura de los datos.
Método
El método de creación de observaciones es relativamente sencillo.
Paso1: Se escoge un valor \(x_i\) de la muestra que pertenece a la clase.
Paso 1: Se selecciona \(k\) vecinos más cercanos de \(x_i\), usualmente se toman los 5 puntos más cercanos de la misma clase.
Paso 2: Se escoge aleatoriamente uno de esos vecinos.
Con este método, hay que cuidar que los datos nuevos sean realistas, para más información se puede leer Chawla et al. (2002).
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321-357. https://jair.org/index.php/jair/article/view/10302/24590
Nyquist, H. (1928). Certain Topics in Telegraph Transmission Theory. Transactions of the American Institute of Electrical Engineers, 47(2), 617-644. https://doi.org/10.1109/T-AIEE.1928.5055024
Quenouille, M. H. (1949). Approximate Tests of Correlation in Time-Series. Journal of the Royal Statistical Society. Series B (Methodological), 11(1), 68-84.