Antes de iniciar el análisis de la Cópulas, repasaremos ciertos conceptos relacionados con las Distribuciones Conjuntas y Marginales de determinadas variables aleatorias.
8.2 Distribución Conjunta
Una forma de extender el caso univariado de funciones para un determinado conjunto de variables aleatorias \(X_1,X_2,...,X_n\), cada variable aleatoria induce una medida de probabilidad, esta medida puede analizarse como el caso de una sola variable, mediante una función denominada Distribución Conjunta la cual la definimos como:
Para el caso bidimensional usaremos el par ordenado de variables aleatorias \((X,Y)\), denominado variable bidimensional aleatoria. Por lo que definimos la Distribución Conjuta como:
\[F(x,y)=P(X\leq x,Y \leq y)\]
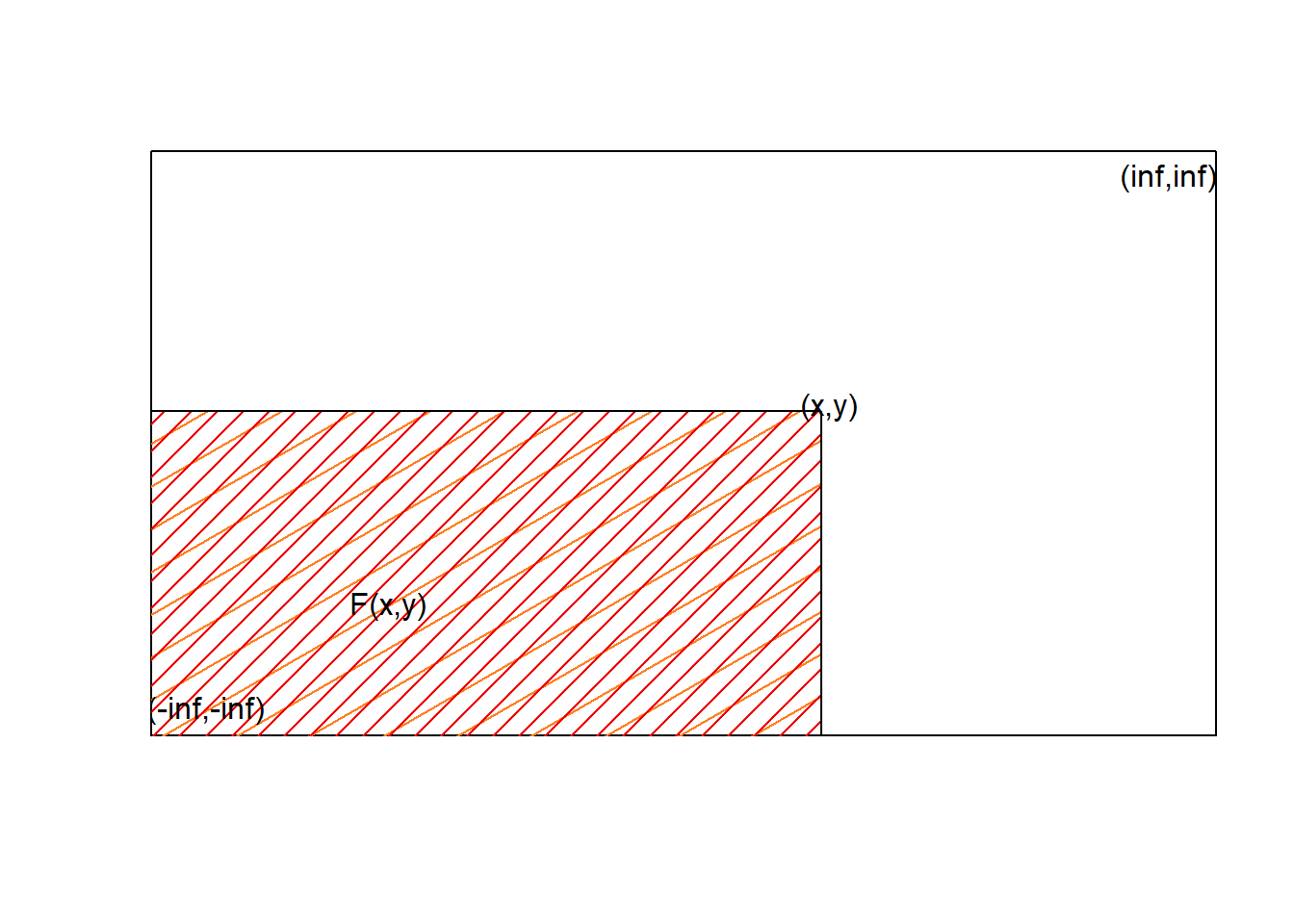
El resultado de \(F(x,y)\) no es más que la probabilidad que que la variables bidimensional aleatoria tome valores en la región delimitada por \(]\infty,x]\text{x}]\infty,y]\)
plot(NA, xlim =c(-25, 100), ylim =c(-25, 100), type ='n',xlab ='', ylab ='',xaxt="n",yaxt="n")polygon(c(-150, 55,55,-150),c(-150,-150, 45,45), col ="chocolate1",density =5, angle =30)polygon(c(-150, 55,55,-150),c(-150,-150, 45,45), col ="red2",density =10, angle =45, border ="black")text(x =56, y =46, label ="(x,y)")text(x =0, y =0, label ="F(x,y)")text(x =-23, y =-24, label ="(-inf,-inf)")text(x =99, y =99, label ="(inf,inf)")
Las funciones de Distribución Conjunta, posee ciertas características similares a la distribución univariada, veremos estas propiedades para el caso de una varaible bidimensional aleatoria, pero se pueden generalizar para mayores dimensiones:
\(lim_{x,y\to\infty}F(x,y)=1\) el caso de ambas variables.
\(lim_{x,y\to-\infty}F(x,y)=0\) el caso de alguna variable.
\(F(x,y)\) es no decreciente en cada variable.
\(F(x,y)\) es continua por la derecha en cada variable.
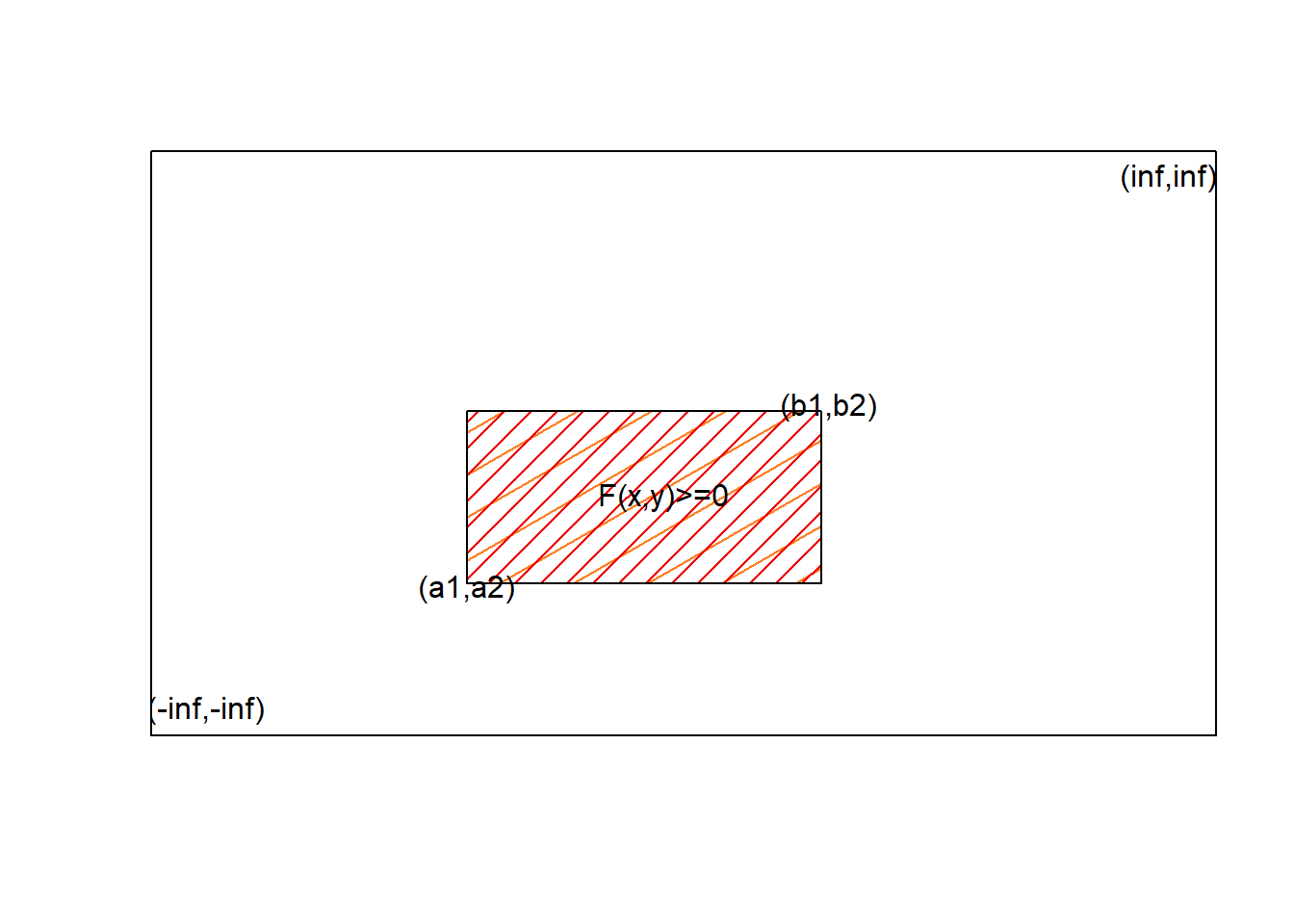
Si \(a_1 < b_1\) y \(a_2 < b_2\) entonces:
\[F(b_1,b_2)-F(a_1,b_2)-F(b_1,a_2)+F(a_1,a,2)\geq 0\] en cualquier región la probabilidad es positiva.
plot(NA, xlim =c(-25, 100), ylim =c(-25, 100), type ='n',xlab ='', ylab ='',xaxt="n",yaxt="n")polygon(c(10, 55,55,10),c(5,5, 45,45), col ="chocolate1",density =5, angle =30)polygon(c(10, 55,55,10),c(5,5, 45,45), col ="red2",density =10, angle =45, border ="black")text(x =56, y =46, label ="(b1,b2)")text(x =10, y =4, label ="(a1,a2)")text(x =35, y =25, label ="F(x,y)>=0")text(x =-23, y =-24, label ="(-inf,-inf)")text(x =99, y =99, label ="(inf,inf)")
al igual que el caso univariado, existe una función de densidad o de masa (\(f(u,v)\)) tal que:
donde \(f(u,v)\) es una función no negativa que cumple:
\(f(u,v)\geq 0\, \forall u,v \in \mathbb{R}\)
\[\int \int f(u,v)dvdu=1\]
8.3 Distribución Marginal
La distribución marginal es la distribución de probabilidad de un subconjunto de variables aleatorias de un conjunto de variables aleatorias. En otras palabras la distribución marginal de el subconjunto \(x_i,x_{j},...x_{p}\) tal que \(x_i,x_{j},...x_{p} \in \{x_1,x_2,...,x_n \}\) es la distribución conjunta del subconjunto sin necesidad de conocer los valores de las otras variables.
Esto es diferente a la llamada distibución condicional, que brinda las probabilidades de un subconjunto dado que se conoce el valor de las otras variables.
Para el caso de dos variables, tenemos la distribución conjunta de (\(X,Y\)) denomimada \(F(x,y)\), la distribución marginal \((F_X (x))\) de \(X\) se estima omitiendo la información referente a Y, por medio de la Teorema de la Probabilidad total tenemos que:
Sea X,Y variables aleatorias independientes, con funciones de distribución \(F_X,F_Y\) respectivamente y con distribución conjunta \(F(X,Y)\). Se dice que son independientes si
\[F(X,Y)=F_X(x)F_Y(y)\]
Medidas Marginales
Para las medidas marginales de la variables bidimensional aleatoria \((X,Y)\), con una m.a.s \(\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n) \}\) son la siguientes:
Medida
Teórica
Muestral
Media Marginal de \(X\)
\(\mu_x=E_X[x]=\int xdF_x=\int xf_X(x)dx\)
\(\hat \mu_x=\bar x=\frac{1}{n}\sum x_i\)
Media Marginal de \(Y\)
\(\mu_y=E_Y[y]=\int ydF_y=\int yf_Y(y)dy\)
\(\hat \mu_y=\bar y=\frac{1}{n}\sum y_i\)
Varianza Marginal Poblacional de \(X \; (Var_X[x])\)
\(\sigma^2_x=E_X[(x-\mu_x)^2]\)
\(S_x^2= \frac{1}{n}\sum x_i^2-\bar x^2\)
Varianza Marginal Poblacional de \(Y \; (Var_Y[y])\)
Si \(X\) y \(Y\) son variables aleatorias independientes, entonces \(\sigma_{xy}=0\), el reciproco es falso, aunque si son normales bivariantes si se cumple.
Podemos definir las cuasivarianzas muestrales (\(\hat S_{x}\) y \(\hat S_{y}\)), como los estimadores insesgados de la varianzas, por ejemplo:
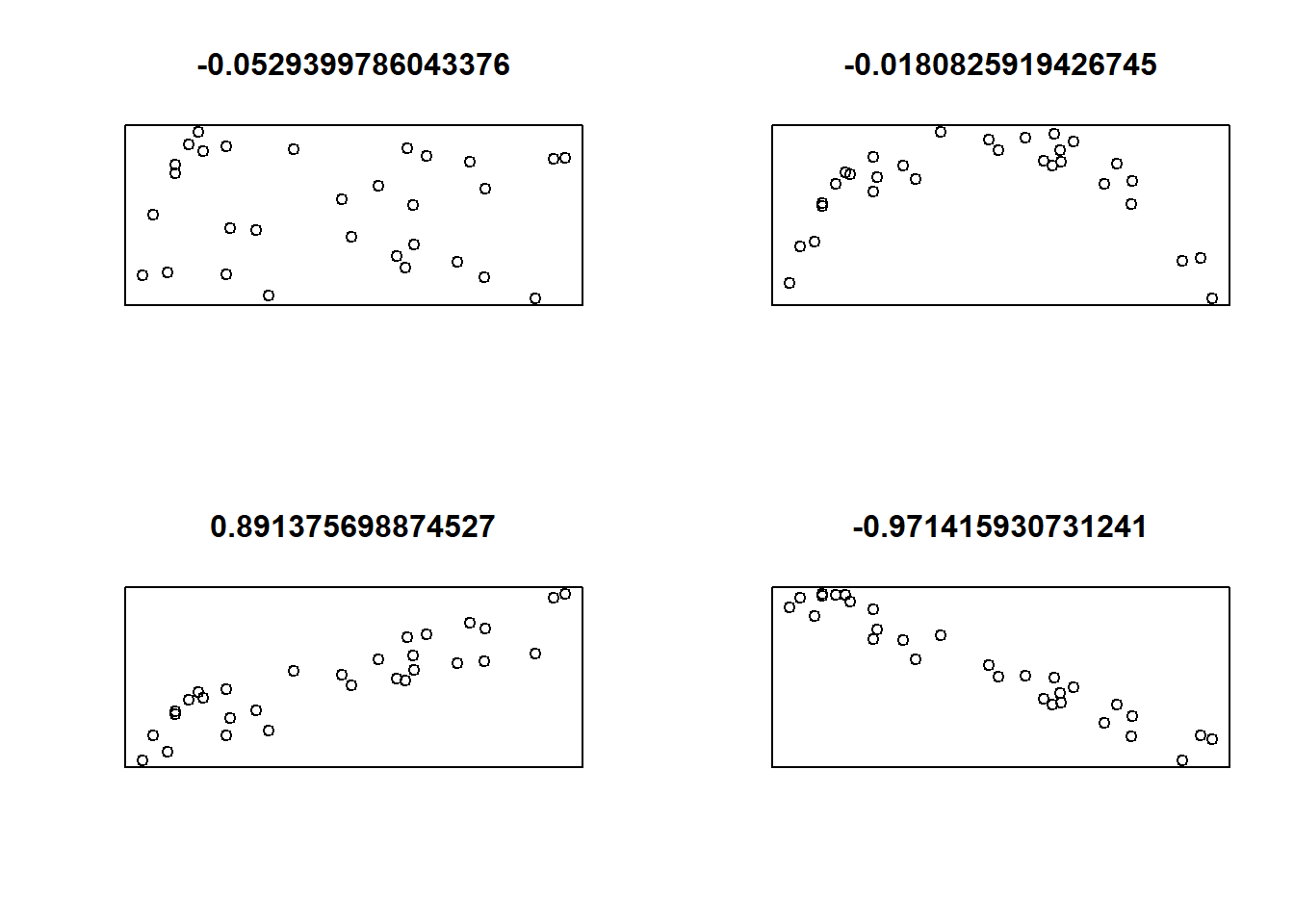
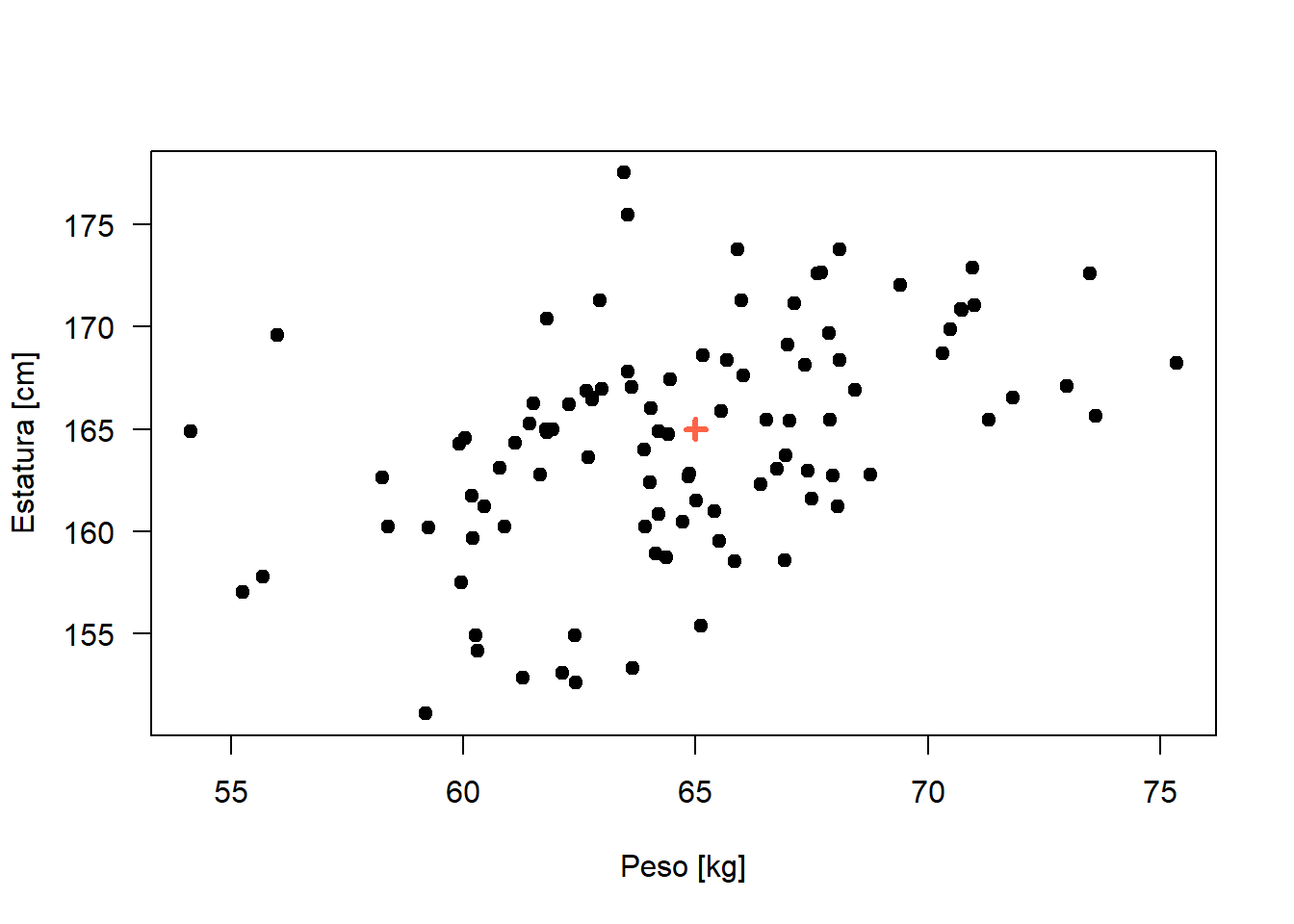
En los gráficos anteriores podemos observar distintos datos, con baja correlación y con alta correlación.
Definición
Dada una m.a.s bidimensional \(\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n) \}\) podemos construir un coeficiente de correlación, que se denomina Coeficiente de correlación de Pearson y lo denotaremos como \(r_{XY}\):
La correlación de Pearson al cuadrado, se denota \(R^2\), es llamada coeficiente de determinación, es usada para medir el poder explicatorio de los modelos lineales, en particular para una regresión lineal
La correlación mide la relación mutua entre dos o más variables, pero no necesariamente indica causalidad, entendiendo como causalidad como que el cambio de una variable produce un efecto sobre la otra. Veamos los siguiente ejemplos:
Ejemplo 1: Cáncer de Piel
Se analizan los datos sobre salud de una población y se determina que existe una alta correlación positiva entre las personas que realizan ejercicios al aire libre y la tendencia de tener cancer, esto es que las personas que hacen ejercicio al aire libre tienden a sufrir cáncer de piel. Esta correlación es significativa y fiable, dado que se ha podido observa en múltiples poblaciones de pacientes. Sin hacer más indagaciones:
¿Se podrá llegar a la conclusión que el ejercicio causa cáncer?
Basándonos en los resultados, un investigador muy creativo, podría llegar a una hipótesis como: “Quizas el estrés del ejercicio causa que el cuerpo pierdaparte de su capacidad para protegerse del daño del sol”
En la realidad, esta correlación podría estar presentandose en los conjuntos de datos porque las personas que realizan ejercicios al aire libre, poseen mayor exposición a la luz del solar, lo que significa que hay más casos de cáncer de piel.
Por lo que ambas variables ( tasa de ejercicio y cáncer de piel) han sido afectadas por una tercera variable causal ( la exposición a la luz solar) pero no existe una relación causal entre el ejercicio y el cáncer de piel.
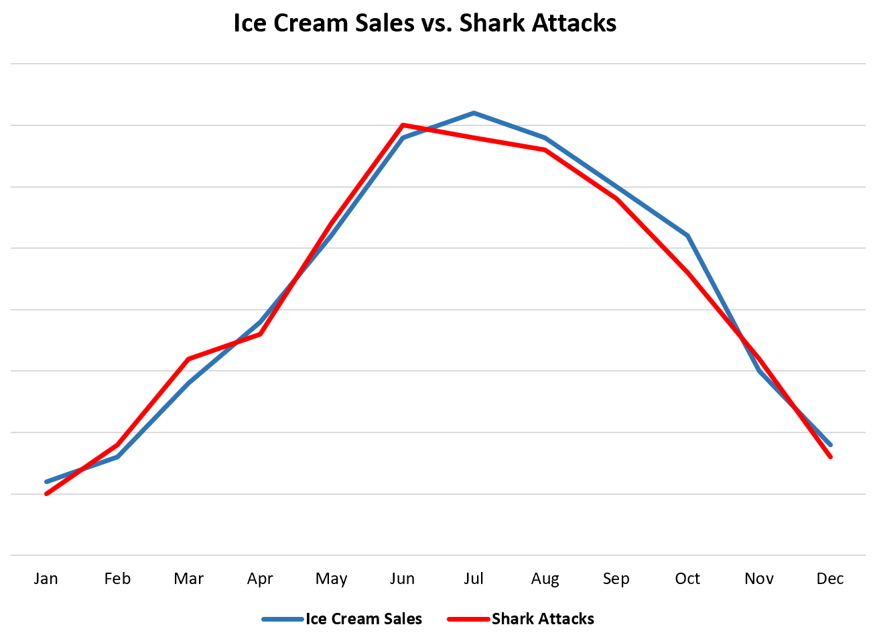
Ejemplo 2: Venta de Helados y Ataques de Tiburones
Venta de Helados vs Ataque de Tiburones
En la figura podemos ver la venta de Helados en Estados Unidos posee un comportamiento similar a los ataques de tiburon reportados, generando una alta correlación, sin embargo, la causalidad entre ambas variables no se puede establecer. Al igual existe una clara tercer variable que es la estación del año, donde en verano aumenta la ventas de helados y aumenta los viajes a las playas, esto último genera más exposición a las personas a los ataques de tiburones.
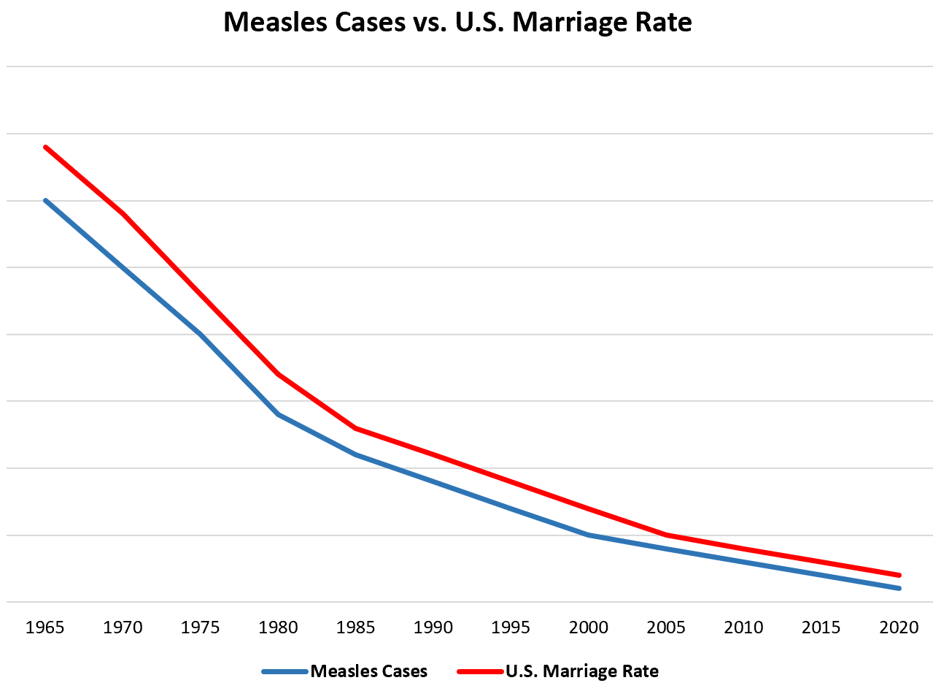
Ejemplo 3: Casos de Sarampión y Tasas de matrimonio
Casos de Sarampión y Tasas de matrimonio
En este caso, la figura nos muestra un comportamiento muy correlacionado entre Casos de Sarampión y las tasas de matrimonio, que claramente no existe una causalidad entre ambas variables, pero incluso encontrar una tercera variable que explique ambos casos no es factible.
Para los casos de Sarampión, su reducción se debe más a factores de los avances de la vacunación y relacionados con la salud y las tasas de matrimonio a temas más socio-demográficos.
Dependencia vs Correlación
En varios modelos utilizan el coeficiente de correlación lineal para medir el grado de dependencia, pero esta práctica como se indicó anteriormente es correcta sólo si las variables aleatorias con que trabajamos se distribuyen conjuntamente según el modelo normal (gaussiano).
8.5 Regresión Lineal Simple
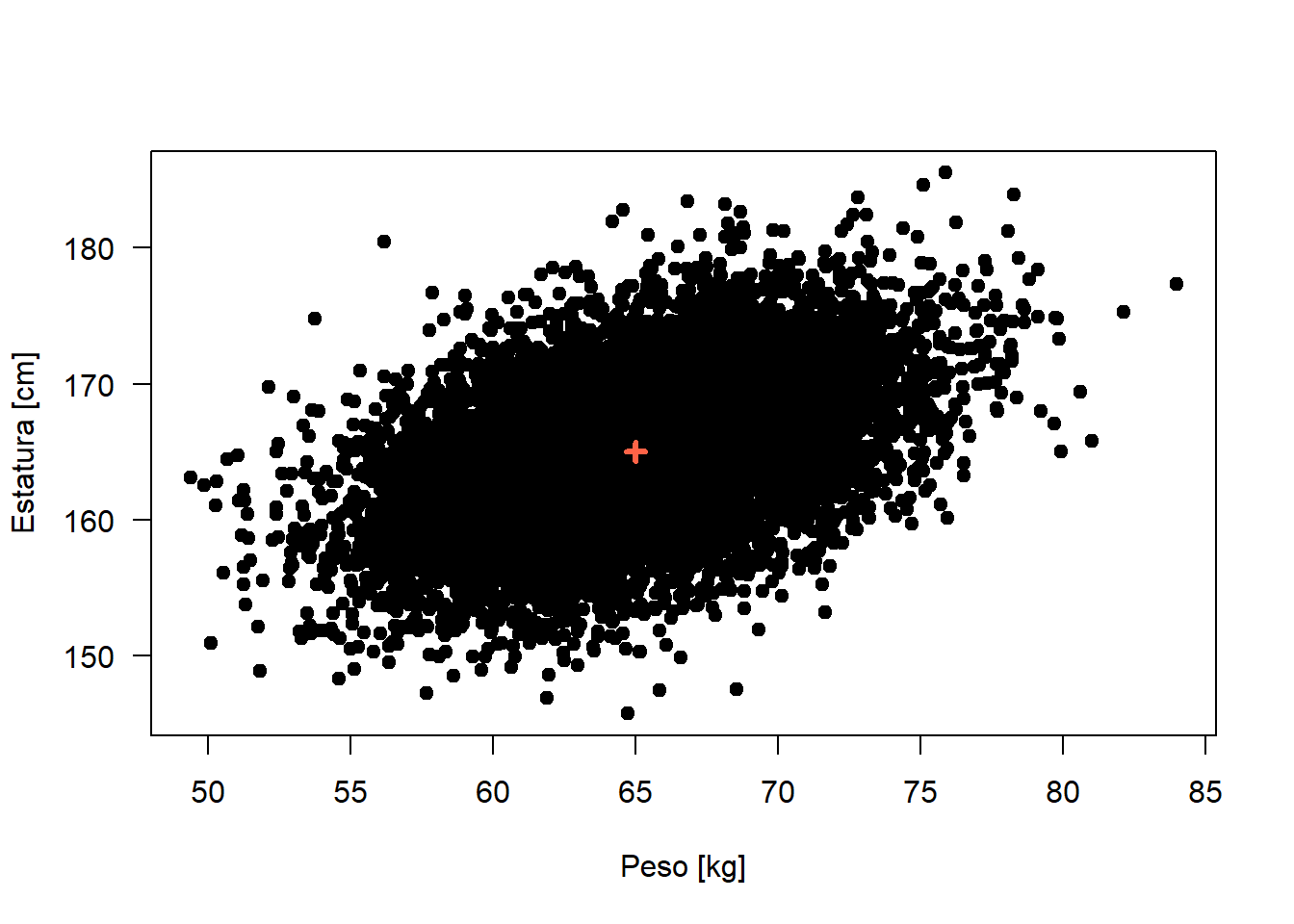
La regresión lineal se remonta a trabajos realizados por Gauss entre 1821 a 1826, el nombre de esta metodología lo recibe por el trabajo de Sir Francis Galton en 1855.
Donde en un estudio sobre la estatura de los padres y los hijos, y observa que los hijos de padres altos son en promedio más bajos y que los hijos de padres bajos son en promedio más altos, como que existiera un “Vuelta Atrás” o una regresión a la media.
La estructura del modelo de regresión lineal simple es el siguiente:
\[Y=\beta_0+\beta_1X+\epsilon\] Esta expresión indica que existen factores que influyen en el valor que toma \(Y\), llamada variable respuesta o dependiente, el primer factor es influencia de la variable explicativa o independiente \(X\) y el segundo un factor no controlado que lo llamaremos error \(\epsilon\) y asumiremos que posee una distribución \(N(0,\sigma^2)\).
El error \(\epsilon\) ocasiona que la dependencia entre \(Y\) y \(X\) no sea perfecta, si no que existe alguna incertidumbre.
Por ejemplo el consumo de gasolina de un vehículo (\(Y\)) influyen la velocidad (\(X\)) y una serie de factores como el tipo de carretera, condiciones climáticas, entre otras que se concentraría en la variable \(\epsilon\).
En caso, que usemos más de una variable explicativa, el modelo es llamado Regresión lineal multiple, y si los datos no son lineales, pero existe una transformación que los linealiza, entonces el modelo recibe el nombre de Regresión Lineal Generalizada.
Por ejemplo un curva de utilidad, bajo el modelo Cobb-Douglas,\(U=A^{\beta_0}B^{\beta_1}\), si le aplicamos la función logaritmo transformamos el problema a uno lineal \(ln(U)=\beta_0 ln(A)+\beta_1 ln (B)\)
Regresando a la expresión de la regresión lineal simple:
\[Y=\beta_0+\beta_1X+\epsilon\]
observe que
\[E[Y]=E[\beta_0+\beta_1X+\epsilon|X=x]=\beta_0+\beta_1x\] Podemos construir un estimador \(\hat Y\) de \(Y\) como
\[\hat Y=\beta_0+\beta_1X\]
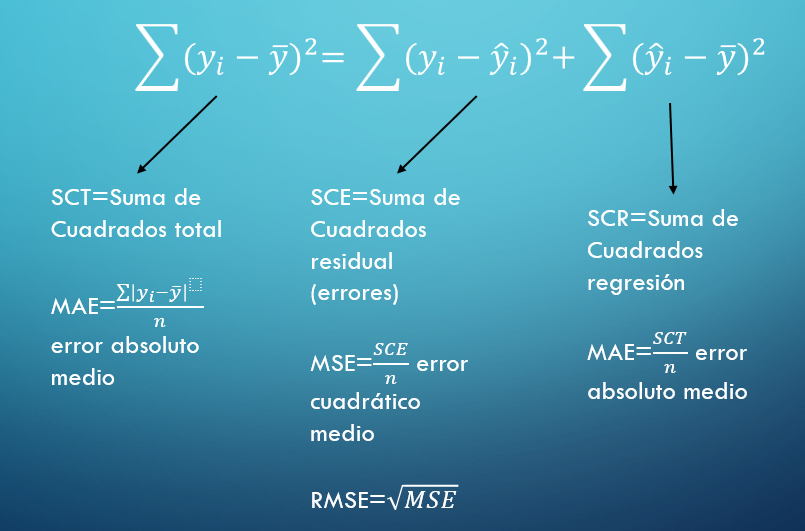
dada una m.a.s \((x_1,y_1),...,(x_n,y_n)\) podemos estimar la suma de los errores al cuadrado:
\[SSE=\sum_{i=1}^n(y_i-\hat y_i)^2=\sum_{i=1}^n(y_i-(\beta_0+\beta_1 x_i))^2\] Si minimizamos el \(SSE\) respecto a \(\beta_0\) y \(\beta_1\) obtenemos que:
\[\beta_1=\frac{S{xy}}{S^2_x}\]
\[\beta_0=\bar y-\beta_1 \bar x\] Finalmente para determinados análisis, como el ANOVA, se tiene la siguiente igualdad
ANOVA
8.6 Distribución Normal Multivariada
Si \(X=[X_1,X_2,...,X_n]^t\) un vector de variables aleatorias se dice que poseen una distribución normal multivariada y se denota por:
\[X \sim N(\mu,\Sigma)\] donde \(\mu=[\mu_1,\mu_2,..,\mu_n]^t\) vector de medias y matriz de covarianzas
Si \(X=[X_1,X_2,...,X_n]^t\) sigue una distribución normal multivariante si satisface las siguientes condiciones:
Toda combinación lineal \(Y=a_1X_1+\cdots+a_nX_n\) se distribuye normalmente.
Sea \(Z=[Z_1,Z_2,...,Z_m]^t\) donde \(Z_i \sim N(0,1)\), dado el vector \(\mu=[\mu_1,\mu_2,..,\mu_n]^t\) existe una matriz \(A \in \mathbb{M}(n,m)\) tal que: \(X=AZ+\mu\), \(\Sigma=AA^t\)
Hay un vector \(\mu\) y una matriz semidefinida positiva simétrica \(\Sigma\) tal que la función carácterística de X es:
con \(|\Sigma|\) el determinante de la matriz de covarianzas.
Distancia de Mahalanobis
En el análisis de Datos multidimensional, para un vector n-dimensional \(X\) y un punto \(\mu\), se denomina Distancia de Mahalanobis a:
\[d_M(X,\mu)=\sqrt{(x-\mu)^t\Sigma^{-1}(x-\mu)}\] Algunas característica de esta distancia:
\(d_M\) coincide con la distancia euclidia entre datos estandarizados.
\(d_M\) es no depende la dimensión.
\(d_M\) considera las variabilidades de la muestra (varianzas) y las correlaciones entre datos.
\(d_M^2\) bajo distribución normal se distribuye como \(\chi^2_n\)
Nota
Por la condición 1, que toda combinación lineal tiene distribución Normal, podemos concluir que si \(X\) se distribuye normalmente cada distribución marginal \(X_i\) es normal y cualquier subconjunto \(h<n\) es normal mutivariado.
Pero no cualquier conjunto de variables normales, generada una distribución conjunta Normal.
Ejemplo:
Sea v.a \(X \sim N(0,1)\), y sea \(Z\) una v.a. independiente de \(X\) tal que:
\[P(Z=1)=P(Z=-1)=\frac{1}{2}\]
Se define \(Y=XZ\). Esto es equivalente a observar \(X\) y lanzar una moneda,si sale escudo, \(Y\) toma el valor de \(X\), sino \(Y\) toma el valor de \(-X\).
Dado esta definiciones podemos veficar que:
La variable \(Y\) tiene una distribución normal estándar. Esto lo obtenemos por la fórmula de probabilidad total
\[F_{Y}(y)=P(Y\leq y)=P(Y\leq y|Z=1)P(Z=1)+P(Y\leq y|Z=-1)P(Z=-1)\]\[=P(XZ\leq y|Z=1)P(Z=1)+P(XZ\leq y|Z=-1)P(Z=-1)=P(X\leq y)\frac{1}{2}+P(X\geq -y)\frac{1}{2}\] Por la propiedad de simetría de la Normal tenemos que:
\[P(Y\leq y)=P(X\leq y)\frac{1}{2}+P(X\leq y)\frac{1}{2}=P(X\leq y)=F_{X}(y)\] 2. Las variables \(X\) y \(Y\) no son correlacionadas.
Como \(X\) y \(Z\) son independientes y tienen media cero tenemos que:
Las variables \(X\) y \(Y\) no son independientes.
Este resultado es inmeditato ya que \(Y \sim N(0,1)\) mientras que \(Y|X\) solo toma valores de \(x\) o \(-x\)
Analicemos la variable \(W=X+Y\), una combinación lineal entre \(X\) y \(Y\), observemos que la variable \(W\) se anula con probabilidad \(\frac{1}{2}\) o \(W=2x\) con probabilidad \(\frac{1}{2}\). Por lo tanto \(W\) no es normal, apesar que \(X\) y \(Y\) son normales, no correlacionadas.
Al no cumplirse que \(W\) sea normal no se cumple con la condición 1, por lo tanto la conjugada de (X,Y) no es normal bivariada.
Normal Bivariada
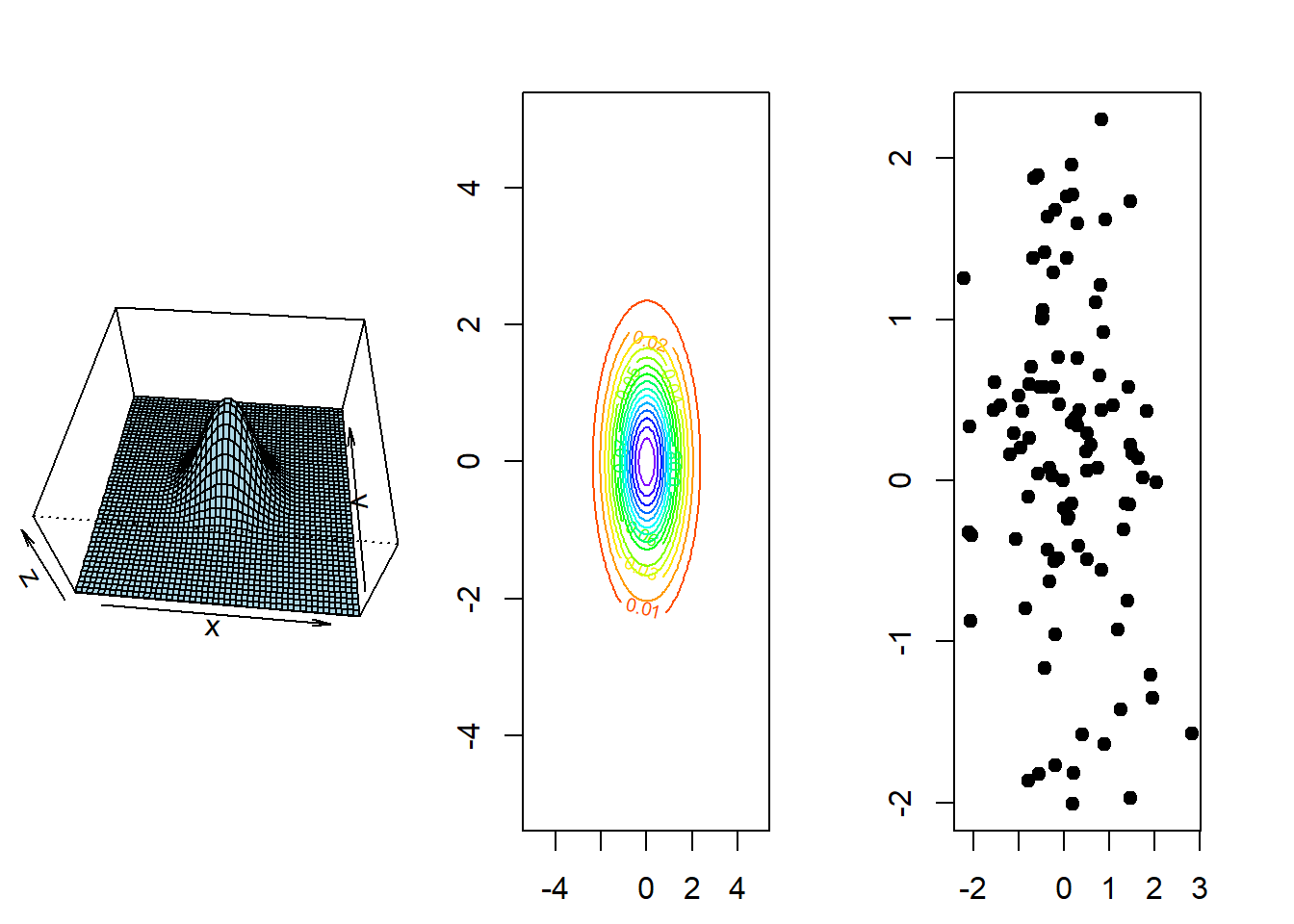
Para las variables aleatorias \(X=(X,Y)^t\) que posee una distribución normal multivariada de dos dimensiones se dice que son normales bivariadas.
Si \(\rho=0\) se puede demostrar que \(f_X(x,y)=f_x(x)f_y(y)\) es decir que son independientes.
Transformación Afín
La condición 1, la podemos expresar como una transformación lineal denominada afín, si definimos \(Y=c+BX\) donde \(c\) es un vector constante Mx1, \(B \in \mathbb{M}(m,n)\) y \(X \sim N(\mu,\Sigma)\) entonces
\[Y\sim N(c+B\mu,B\Sigma B^t)\]
La transformación afin nos permite construir subconjuntos de la variable \(X\) n-dimensional y obtener marginales.
Ejemplo
Sea \(X \sim N(\mu,\Sigma)\) con \(X=[X_1,X_2,X_3,X_4]\) la matriz
Esta característica de la normales bivariadas, de tener un comportamiento eliptico en la nube de puntos, genera una familia denomida distribuciones elipticas (Fang 1990) y también existen las distribuciones esfericas. La principal carácterísticas que existe en estas matrices es su simetría, otra distribución de esta familia es al t-student bivariada.